
Given that we can detect the writing system of the text, it raises the question:
Is it possible to translate text from one language to another using OCR and Tesseract?
To learn how to translate languages using Tesseract and Python, just keep reading.
The short answer is yes, it is possible — but we’ll need a bit of help from the textblob library, a popular Python package for text processing (TextBlob: Simplified Text Processing). By the end of this tutorial, you will automatically translate OCR’d text from one language to another.
Configuring your development environmentTo follow this guide, you need to have the OpenCV library installed on your system.
Luckily, OpenCV is pip-installable:
$ pip install opencv-contrib-pythonIf you need help configuring your development environment for OpenCV, I highly recommend that you read my pip install OpenCV guide — it will have you up and running in a matter of minutes.
Having problems configuring your development environment? Figure 1: Having trouble configuring your dev environment? Want access to pre-configured Jupyter Notebooks running on Google Colab? Be sure to join PyImageSearch University — you’ll be up and running with this tutorial in a matter of minutes.
Figure 1: Having trouble configuring your dev environment? Want access to pre-configured Jupyter Notebooks running on Google Colab? Be sure to join PyImageSearch University — you’ll be up and running with this tutorial in a matter of minutes.All that said, are you:
Short on time?Learning on your employer’s administratively locked system?Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?Ready to run the code right now on your Windows, macOS, or Linux system?Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Learning ObjectivesIn this tutorial, you will:
Learn how to translate text using the TextBlob Python package Implement a Python script that OCRs text and then translates it Review the results of the text translation OCR and Language TranslationIn the first part of this tutorial, we’ll briefly discuss the textblob package and how it can be used to translate text. From there, we’ll review our project directory structure and implement our OCR and text translation Python script. We’ll wrap up the tutorial with a discussion of our OCR and text translation results.
Translating Text to Different Languages with TextBlobTo translate text from one language to another, we’ll use the textblob Python package (https://textblob.readthedocs.io/en/dev/). If you’ve followed the development environment configuration instructions from an earlier tutorial, then you should already have textblob installed on your system. If not, you can install it with pip:
$ pip install textblobOnce textblob is installed, you should run the following command to download the Natural Language Toolkit (NLTK) corpora that textblob uses to automatically analyze text:
$ python -m textblob.download_corporaNext, you should familiarize yourself with the library by opening a Python shell:
$ python>>> from textblob import TextBlob>>>Notice how we are importing the TextBlob class — this class enables us to automatically analyze a piece of text for tags, noun phrases, and yes, even language translation. Once instantiated, we can call the translate() method of the TextBlob class and perform the automatic text translation. Let’s use TextBlob to do that now: UTF8ipxm
>>> text = u"おはようございます。">>> tb = TextBlob(text)>>> translated = tb.translate(to="en")>>> print(translated)Good morning.>>>Notice how I have successfully translated the Japanese phrase for “Good morning” into English.
Project StructureLet’s start by reviewing the project directory structure for this tutorial:
|-- comic.png|-- ocr_translate.pyOur project consists of a funny cartoon image that I generated with a comic tool called Explosm. Our textblob based OCR translator is housed in the ocr_translate.py script.
Implementing Our OCR and Language Translation ScriptWe are now ready to implement our Python script, which will automatically OCR text and translate it into our chosen language. Open the ocr_translate.py in our project directory structure, and insert the following code:
# import the necessary packagesfrom textblob import TextBlobimport pytesseractimport argparseimport cv2# construct the argument parser and parse the argumentsap = argparse.ArgumentParser()ap.add_argument("-i", "--image", required=True,help="path to input image to be OCR'd")ap.add_argument("-l", "--lang", type=str, default="es",help="language to translate OCR'd text to (default is Spanish)")args = vars(ap.parse_args())We begin with our imports, where TextBlob is the most notable for this script. From there, we dive into our command line argument parsing procedure. We have two command line arguments:
--image: The path to our input image to be OCR’d and translated --lang: The language to translate the OCR’d text into — by default, it is Spanish (es)Using pytesseract, we’ll OCR our input image:
# load the input image and convert it from BGR to RGB channel# orderingimage = cv2.imread(args["image"])rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)# use Tesseract to OCR the image, then replace newline characters# with a single spacetext = pytesseract.image_to_string(rgb)text = text.replace("\n", " ")# show the original OCR'd textprint("ORIGINAL")print("========")print(text)print("")Upon loading and converting our --image to RGB format (Lines 17 and 18), we send it through the Tesseract engine via pytesseract (Line 22). Our textblob package won’t know what to do with newline characters present in text, so we replace them with spaces (Line 23).
After printing out our original OCR’d text, we’ll go ahead and translate the string into our desired language:
# translate the text to a different languagetb = TextBlob(text)translated = tb.translate(to=args["lang"])# show the translated textprint("TRANSLATED")print("==========")print(translated)Line 32 constructs a TextBlob object, passing the original text to the constructor. From there, Line 33 translates the tb into our desired --lang. And finally, we print out the translated result in our terminal (Lines 36-38).
That’s all there is to it. Just keep in mind the complexities of translation engines. The TextBlob engine under the hood is akin to services such as Google Translate, though maybe less powerful. When Google Translate came out in the mid-2000s, it wasn’t nearly as polished and accurate as today. Some may argue that Google Translate is the gold standard. Depending on your OCR translation needs, you could swap in an API call to the Google Translate REST API if you find that textblob is not suitable for you.
OCR Language Translation ResultsWe are now ready to OCR our input image with Tesseract, and then translate the text using textblob. To test our automatic OCR and translation script, open a terminal and execute the commands shown in Figure 2 (right). Here, our input image on the left, contains the English exclamation, “You told me learning OCR would be easy!” This image was generated using the Explosm comic generator. As our terminal output shows, we successfully translated the text to Spanish, German, and Arabic (a right-to-left language).
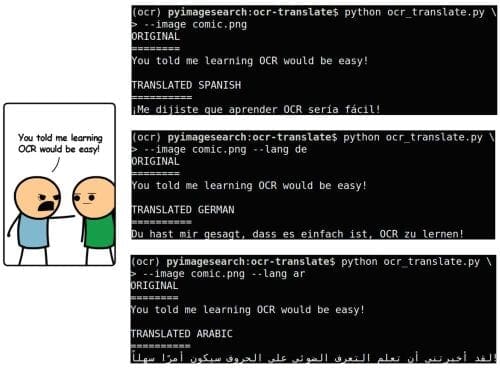 Figure 2. The results of Tesseract for OCR and textblob for translation of the exclamation “You told me learning OCR would be easy!” into its Spanish, German, and Arabic equivalents.
Figure 2. The results of Tesseract for OCR and textblob for translation of the exclamation “You told me learning OCR would be easy!” into its Spanish, German, and Arabic equivalents.OCR’ing and translating text is quite easy once you use the textblob package!
What's next? We recommend PyImageSearch University.Course information:86 total classes • 115+ hours of on-demand code walkthrough videos • Last updated: October 2024★★★★★ 4.84 (128 Ratings) • 16,000+ Students EnrolledI strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
✓ 86 courses on essential computer vision, deep learning, and OpenCV topics✓ 86 Certificates of Completion✓ 115+ hours of on-demand video✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques✓ Pre-configured Jupyter Notebooks in Google Colab✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch✓ Easy one-click downloads for code, datasets, pre-trained models, etc.✓ Access on mobile, laptop, desktop, etc.Click here to join PyImageSearch University
SummaryIn this tutorial, you learned how to automatically OCR and translate text using Tesseract, Python, and the textblob library. Using textblob, translating the text was as easy as a single function call.
In our next tutorial, you’ll learn how to use Tesseract to automatically OCR non-English languages, including non-Latin writing systems (e.g., Arabic, Chinese, etc.).
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!
 Download the Source Code and FREE 17-page Resource Guide
Download the Source Code and FREE 17-page Resource GuideEnter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!