1.软件:SQL service 2008
2.只需在正确答案的前面选中即可(都为单选题) ,在应用题中一空可能会有多个答案选项,在填写答案时要全部写上且要用顿号(、)隔开
3.考试时间为120分钟(上机考试 ),考试结束前5分钟系统会报警提醒考生存盘,考试时间为0自动交卷。
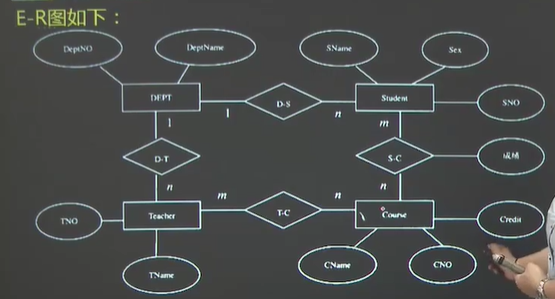
第一章 数据库应用系统开发方法①掌握数据库的基本概念。
②了解软件工程和数据库技术
③理解DBAS生命周期模型
第一节 基本概念 1.数据1)数据:是数据库中存储的基本对象。
定义:描述事物的符号序列。
数据的种类:数字、文字、图形、图像声音以及其他特殊符号。
2)计算机中的数据分为两个部分:①临时性数据(程序运行时产生的数据,保存在内存中,内存在断电时所有的数据都回消失);②持久化数据(存储在磁盘中的数据)
3)数据有型和值的划分
型表示数据的类型(例如整型,字符型等等);值表示给出了符合给定型的值。
2.数据库(DataBase)——DB 1)数据的集合,**具有统一的结构形式并存放在统一存储介质中**,是多种应用数据的集成,可被多个应用程序所共享。 2)按照数据提供的数据模式存储
3)数据库的体现——二维表
3、数据库应用系统——DBAS 组成:数据库系统,应用程序,应用界面
第二节 软件工程与数据库技术 一)定义 软件工程是由工程、科学和数学的原则与方法来开发和维护计算机软件的相关技术和管理方法。
组成:软件工程由方法、工具、过程组成——这就是软件工程的三要素。
二)软件生命周期 定义:一般来说,软件产品从定义开始,经过开发、使用和维护,直到退役的全过程称为软件生命周期。
三)数据库工程 1、数据库应用系统的开发本身就是软件工程但是又有自己的特点,所以特称为数据库工程。数据库工程分为两个部分:①数据库设计;②是数据库相应的应用的设计与实现
2、数据库应用系统的设计开发必须要有软件过程模型作为指导
3、典型的软件开发模型:瀑布模型、快速原型模型、螺旋模型、增量模型等等
第三节 DBAS的生命周期模型 1、参照软件开发模型的瀑布模型,DBAS的生命周期模型有项目规划、需求分析、系统设计、系统实现与部署、运行管理与维护。
2、根据DBAS的软件组成和各自的功能,数据组织与存储设计(后台)、数据访问与处理设计、应用设计三条设计主线,分别用于设计数据库、数据库事务和应用程序。
3、根据数据库三级模式(外模式,概念模式(模式),内模式),DBAS设计阶段分为概念设计,逻辑设计和物理设计三个步骤。
DBAS生命周期模型图
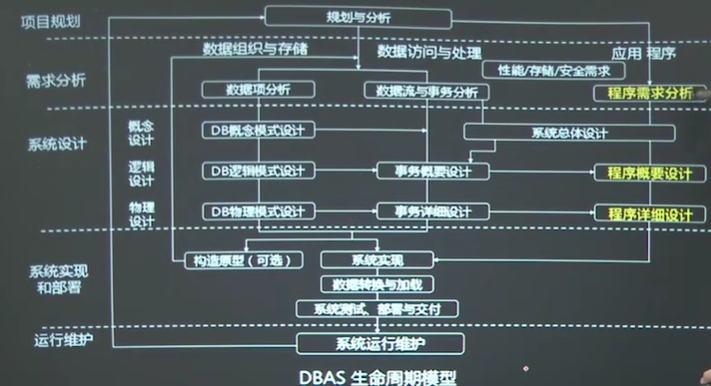
4、规划与分析的主要工作内容:系统规划与定义、可行性 分析、项目规划

5、需求分析(干什么)的主要工作:数据需求分析。功能需求分析、性能需求分析、其他需求分析。

6、系统设计(怎么干)

(1)下列属于数据库设计内容的是 ( B )
A.需求分析和维护
B.概念结构设计和逻辑结构设计
C.功能设计和测试用例设计
D.结构设计和行为设计
(2)下列不属于DBAS可行性分析的是 ( C )
A技术可行性
B操作可行性
C.结构可行性
D.经济可行性
(3)下列不属于运行维护工作的是 ( C )
A.系统监控
B系统性能优化
C.应用系统重写
D.系统升级
(4) 第四题答案为 A

(5) 第五题答案为 B

(6)第六题答案为 A

(7)第七题答案为 D

1、需求:是指用户对软件的功能和性能的要求,就是用户想要软件干什么,完成什么样的功能,达到什么性能。
2、需求分析是计算机系统的软件功能分配和软件设计之间起重要桥梁作用的软件工程活动。描述待开发的系统要完成的功能。
需求分析时指明软件和系统其他元素的接口并建立软件必须要满足的的约束。
3.注意:①软件功能越复杂,需求分析的工作就越复杂;②用户需求的不明确性导致需求的可变性,从而导致需求分析工作的复杂;③软件产品的不可见性——即开发人员对具体的需求不了解(例如在开发人员开发系统时不了解取款机取款三次密码错误就会吞卡等等)。

4、需求获取的方法
①面谈

②实地观察——在别人已有的产品或者产品对换环境有依赖时;

③问卷调查——访谈对象多时且需要许多的细节问题需要了解时,时间尽可能的短,最好是单选题且有自己的答案;
④查阅资料——向对象公司借阅他们的资料了解
二、需求分析1、需求分析的过程(该步骤建立在已经获取了需求的基础上)
①标识问题—>②建立需求模型—>③描述需求—>④确认需求

2、需求分析的方法
1)结构化分析及建模方法(SAD)——如DFD模型(数据流图)、IDEF模型;
①注意:结构化分析及设计方法是瀑布模型的首次实践。
②结构化分析的任务:建立分析模型—>编写需求规格说明书(SRS)—>结构化分析的指导思想(抽象与分解)
注意SA表示结构化分析

2)面向对象分析和建模方法(OOA)——UML用例建模(第五章讲)
3、DFD需求建模方法——核心是数据流。

1)DFD的常用图形符号
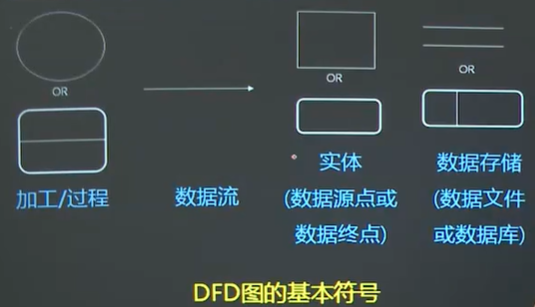
2)数据流(数据流动的方向)——数据在系统内传播的路径,因此由一组成分固定的数据组成;就是流动中的数据,由名词或者名词短语来命名。

3)数据源和数据加工(处理)

4)注意:DFD图(数据流程图)主要是对功能进行建模,就是业务流程
5)DFD图(数据流程图)的具体建模的过程和步骤:明确目标和确定系统边界(将用户对目标系统的功能需求完整、准确、一致的描述出来 )—>建立顶层DFD图 (顶层DFD只有一张),顶层DFD是对系统的一个大概的概括,没有具体的细节,说明系统的边界(系统的输入和输出)——>构建第一层DFD分解图(中间层DFD )——>开发DFD层次结构图(底层DFD原则:保持均匀的深度模型,按困难程度进行选择),由不可再分的过程组成。
6)确认DFD的五条规则:

4、常用的IDEF0~IDEF4:
①IDEF0:描述系统功能及其相互关系
②IDEF1:系统信息及其数据的关系
③IDEF2:系统模拟,动态建模
④IDEF3:过程描述及获取方法
⑤IDEF4:面向对象设计
5、UML用例模型

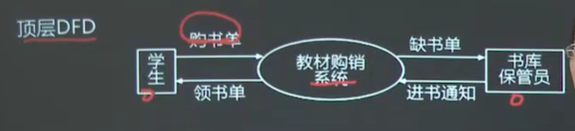
1)教材购销系统:

解答:顶层DFD
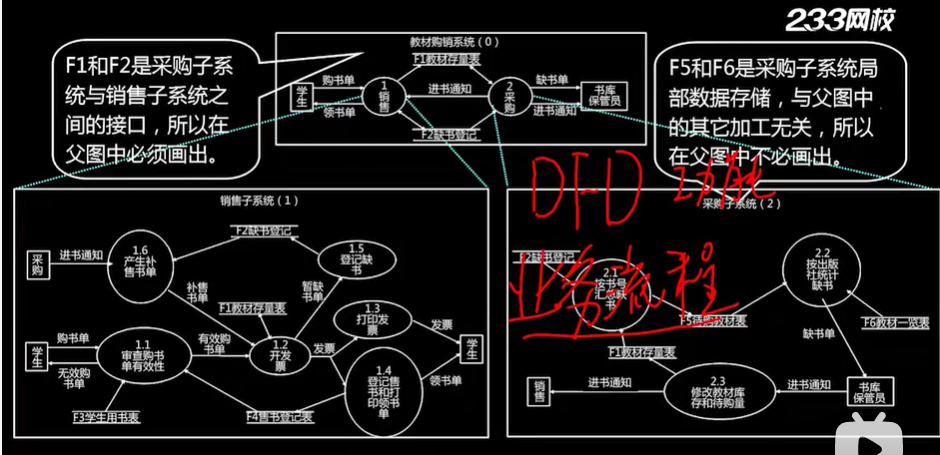
中间层和底层DFD
2)

3)

4)

5)

数据库概念设计是数据库设计的核心环节。通过对用户的需求进行综合、归纳与抽象,形成一个独立于DBMS的概念模型。
一、数据库概念设计的目标
一)依据
数据库概念设计以需求分析的结果为依据,即需求说明书、DFD图以及在需求阶段收集到的应用领域中的各类报表。
二)结果
概念设计的结果是概念模型(E-R图)以及概念设计说明书。
三)过程
①明确建模目标(模型覆盖范围);②定义实体集(自底向上识别和定义实体);③定义联系(实体间的关联关系);④建立信息模型(构建ER模型);⑤确定实体的属性(属性描述实体的特征和性质);⑥对信息模型进行集成与优化(检查和消除命名不一致、结构不一致)
概念模型是对现实世界的抽象和模拟。
四)概念模型设计
概念设计目前采用的最广泛的是E-R建模方法。将现实世界抽象为具有属性的实体及联系。
五)与E-R建模有关的的概念
1)实体:客观存在并可相互区分的事物叫实体;实体集:同型实体的集合称之为实体集;属性:实体具有的某一特性,一个实体具有若干个属性来刻画,每个属性的取值范围称为域(用来描述实体的性质和特征);码或键:实体集中唯一标识每个实体的属性或属性组合;主键或主码:用来区别同一个实体集不同实体的键(主码的值不能相同)。
2)联系:描述实体间的相互关系;联系集:同类联系的集合称之联系集 ;三类联系:一对一(1:1)、一对多(1:n)、多对多(m:n)
IDEF1X是数据建模的方法
第二节 数据库逻辑设计 一)逻辑设计的任务 将概念模型(ER图)转换为DBMS支持的数据模型(关系模型),并对其进行优化。
二)数据模型 有三种:层次模型、网状模型、关系模型(当前最流行的数据模型)
三)关系模型 关系模型用二维表来表示;关系的描述称为关系模式;关系模式由五部分组成,即五元组:R(U,D,DOM,F)

E-R图到关系模式的转换:


①函数依赖(Functional Dependency,FD)
这种依赖关系类似于数学中的函数y=f(x),自变量x确定之后,相应的函数值y也就唯一地确定了。
如关系:公民(身份证号,姓名,地址,工作单位)
身份证号一确定,则其地址就唯一确定,因此地址函数依赖身份证号。而姓名一确定,不一定能确定地址。
②多值依赖(Multivalued Dependency,MD)
教师号可能多值依赖课程号,因为给定一个(课程号,参考书号)的组合,可能有对应多个教师号。这是因为多个老师可以使用相 同或不同的参考书上同一门课。
简单点讲,函数就是唯一确定的关系;多值依赖却不能唯一确定。
七)函数依赖的几种特例1、平凡函数依赖与非平凡函数依赖
如果X→Y,且Y ⊄ X,则X→Y 称为非平凡函数依赖。
若Y ⊆ X ,则称X→Y为平凡函数依赖。
由于Y ⊆ X 时,一定有X→Y,平凡函数依赖必然成立,没有意义,所以一般所说的函数依赖总是指非平凡函数依赖。
举例:
例:Sno代表学生的学号,Cno代表课程号,Grade代表成绩。
在关系 SC(Sno, Cno, Grade)中,
非平凡函数依赖:(Sno, Cno)→Grade 即Grade不包含于(Sno, Cno)
平凡函数依赖:(Sno, Cno)→Sno 即Sno包含于(Sno, Cno)
(Sno, Cno)→Cno
2、完全函数依赖与部分函数依赖
如果X→Y ,且对于任何X’ ⊂ X,都有X’
Y,则称y完全依赖于x,记作X->Y(箭头上有个大写f)。
如果X→Y,但Y不完全依赖于X,则称Y部分函数依赖于X,记作X->Y(箭头上有个大写P)。
例:选课(学号,课程号,课程名,成绩)
(学号,课程号) X->Y(箭头上有个大写f) 成绩 即(学号,课程号)两者都为主键且共同决定成绩,缺一不可
(学号,课程号)X->Y(箭头上有个大写P) 课程名因为课程号→课程名 即(学号,课程号)两者都为主键且课程号可以单独决定课程名。
推论:如果X→Y ,且X是单个属性,则X->Y(箭头上有个大写f)
3、传递函数依赖
如果X→Y , Y→Z,且Y 不包含于X, Y不依赖X,则称Z传递函数依赖于X。记作X 传递→Z 。
例:学生(学号,姓名,系名,系主任)
显然系主任传递函数依赖于学号,因为学号→系名,系名→系主任
思考题:已知关系模式R(学生学号,课程名,学生专业号,专业名,成绩),说出下面是什么关系?
(学生学号,课程名,学生专业号)成绩 (部分函数依赖)
学生学号 专业名 (传递函数依赖)
(学生学号,专业名)成绩 (不是依赖关系)
(学生学号,课程名)成绩 (完全函数依赖)
(课程名,专业名,成绩) (课程名,成绩) (平凡函数依赖)
八)数据规范化关系数据库的设计主要是关系模式设计。关系模式设计的好坏直接影响到数据库设计的成败。将关系模式规范化,是设计较好的关系模式的惟一途径。
关系模式的规范化主要是由关系范式来完成的。
关系模式的规范化:把一个低一级的关系模式分解为高一级关系模式的过程。
关系数据库的规范化理论是数据库逻辑设计的工具。
目的:尽量消除插入、删除异常,修改复杂,数据冗余的问题。
九)范式范式:关系模式满足的约束条件称为范式。根据满足规范化的程度不同,范式由低到高分为1NF,2NF,3NF,BCNF,4NF,5NF。
①1NF:如果关系模式R,其所有属性都是不可再分的基本数据项,则称R属于第一范式,R∈1NF。1NF要求数据库表中的字段都是单一属性的,不可再分。即元素具有原子性。
②2NF:如关系模式R∈1NF,且每个非主属性完全函数依赖于主码,则称R属于第二范式,R∈2NF。2NF要求实体的属性完全依赖于 主关键字。首先关系要满足第一范式。
例:判断R (学号,姓名,年龄,课程名称,成绩,学分)是否属于第二范式。
主码:(学号,课程名称)
非主属性:姓名,年龄,成绩,学分
存在如下决定关系: (学号, 课程名称)→(姓名,年龄,成绩,学分) 但(课程名称)→(学分)
(学号)→(姓名, 年龄)所以R不属于2NF
③第三范式:如果关系模式为2NF,并且R中的每个非主属性不传递依赖于R的主键,则称关系R是是属于第三范式,即R∈2NF。
范式之间的关系:

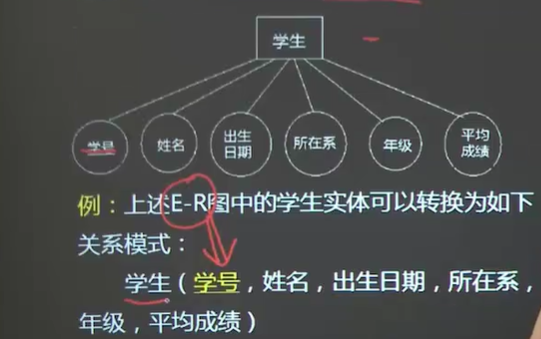
十)数据库逻辑模型的产生(ER图转换为关系模式) ①一个实体转换成一个关系模式;②一个1:1联系可以转换为一个独立的关系模式,也可以于任意一端对应的关系模式合并;
③一个1:n联系可以转化为一个独立的关系模式,也可以于n端对应的关系模式合并;④一个n:m转换为一个关系模式;⑤三个或三个以上实体的多元联系转换为一个关系模式;⑥同一实体集实体间的联系可以按照1:1、1:n、n:m三种情况进行处理。
举例:
①1:1联系的E-R图转换为关系模式较为简单,不在列举,总共有情况;
②1:n联系的E-R图转换为关系模式,有两种方案;
方案一:仓库(仓库号、地点、面积)、产品(产品号、产品名、价格)、仓储(仓库号、产品号、数量)
方案二:仓库(仓库号、地点、面积)、产品(产品号、产品名、价格、仓库号、数量)
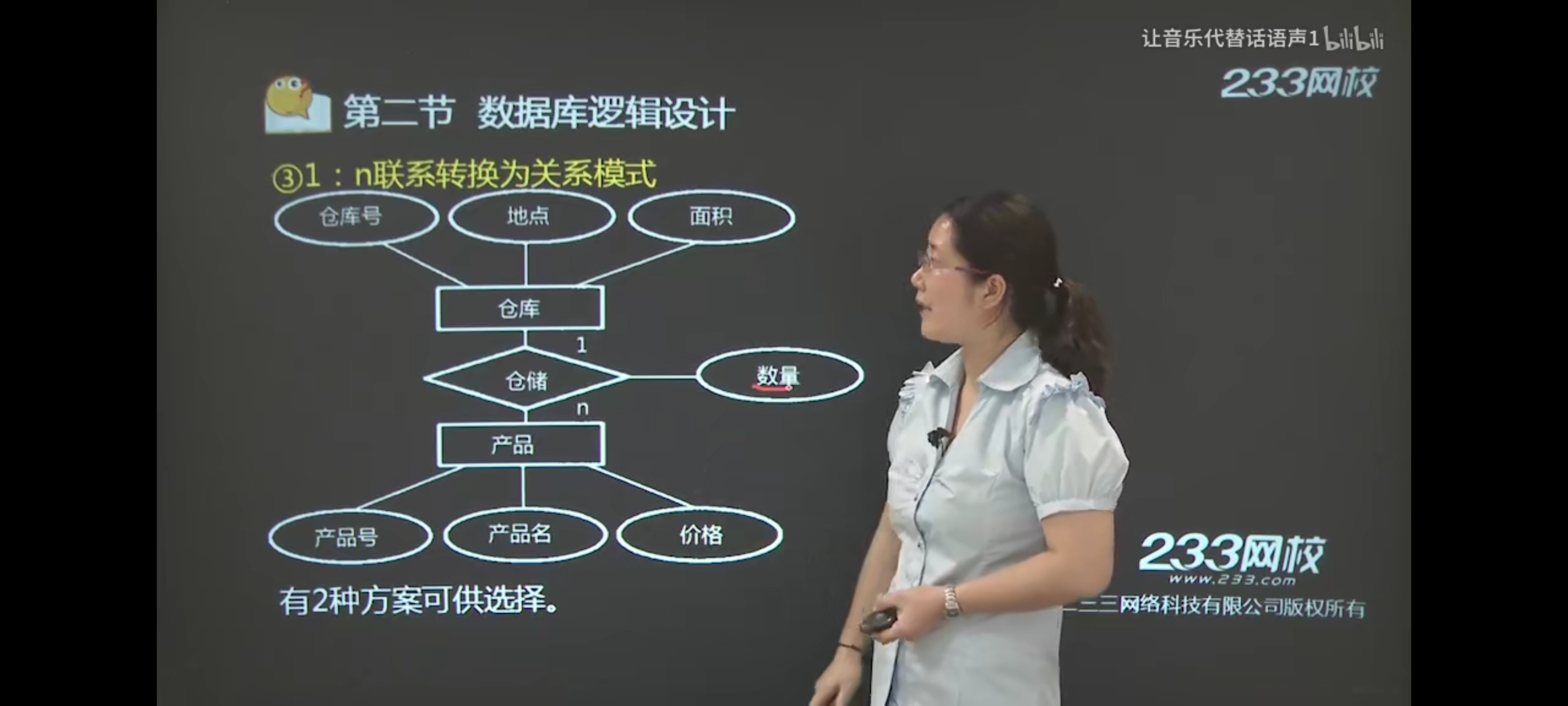
③m:n联系的E-R图转换为关系模式,有一种方案;
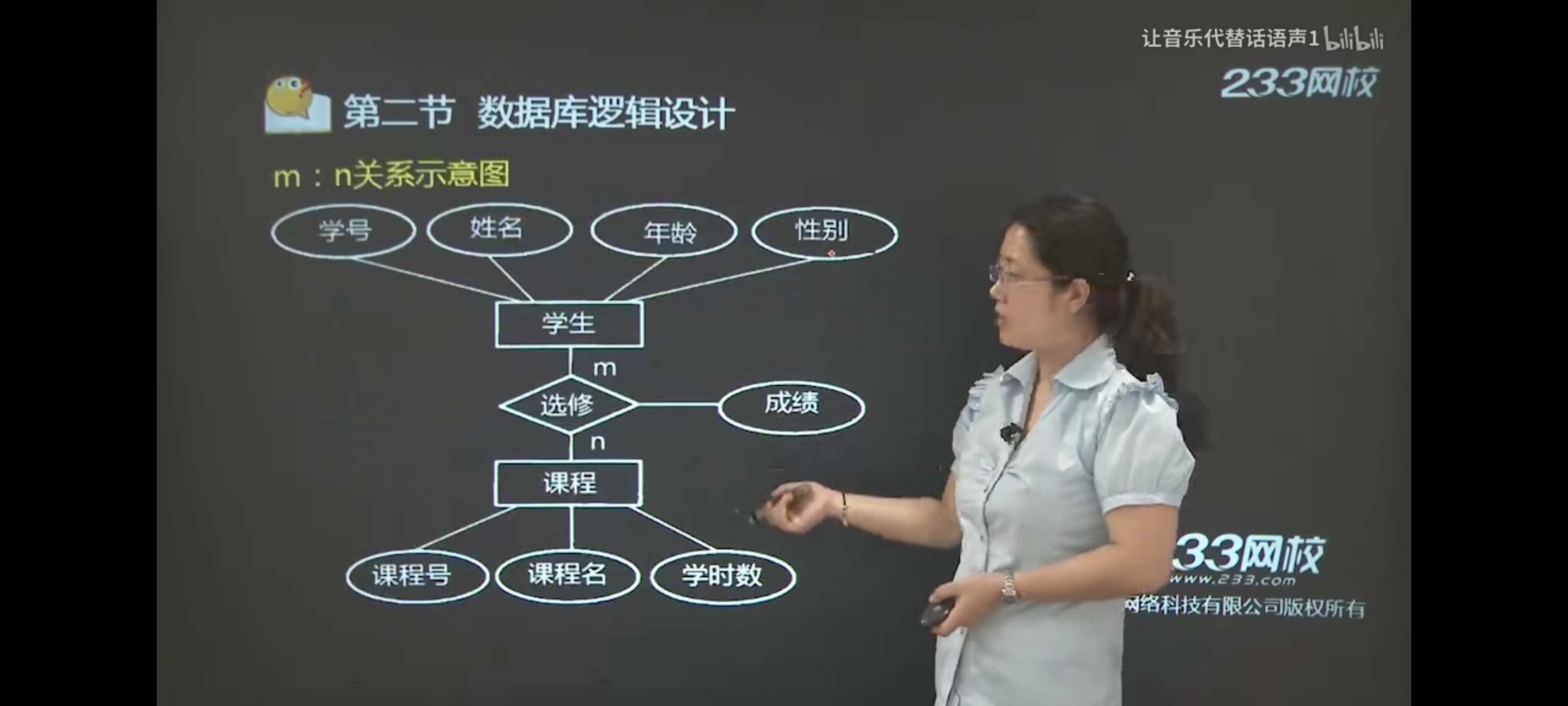
方案一:学生(学号、姓名、年龄、性别)、课程(课程号、课程名、学时数)、选修(学号、课程号、成绩)
④三个及三个以上实体:


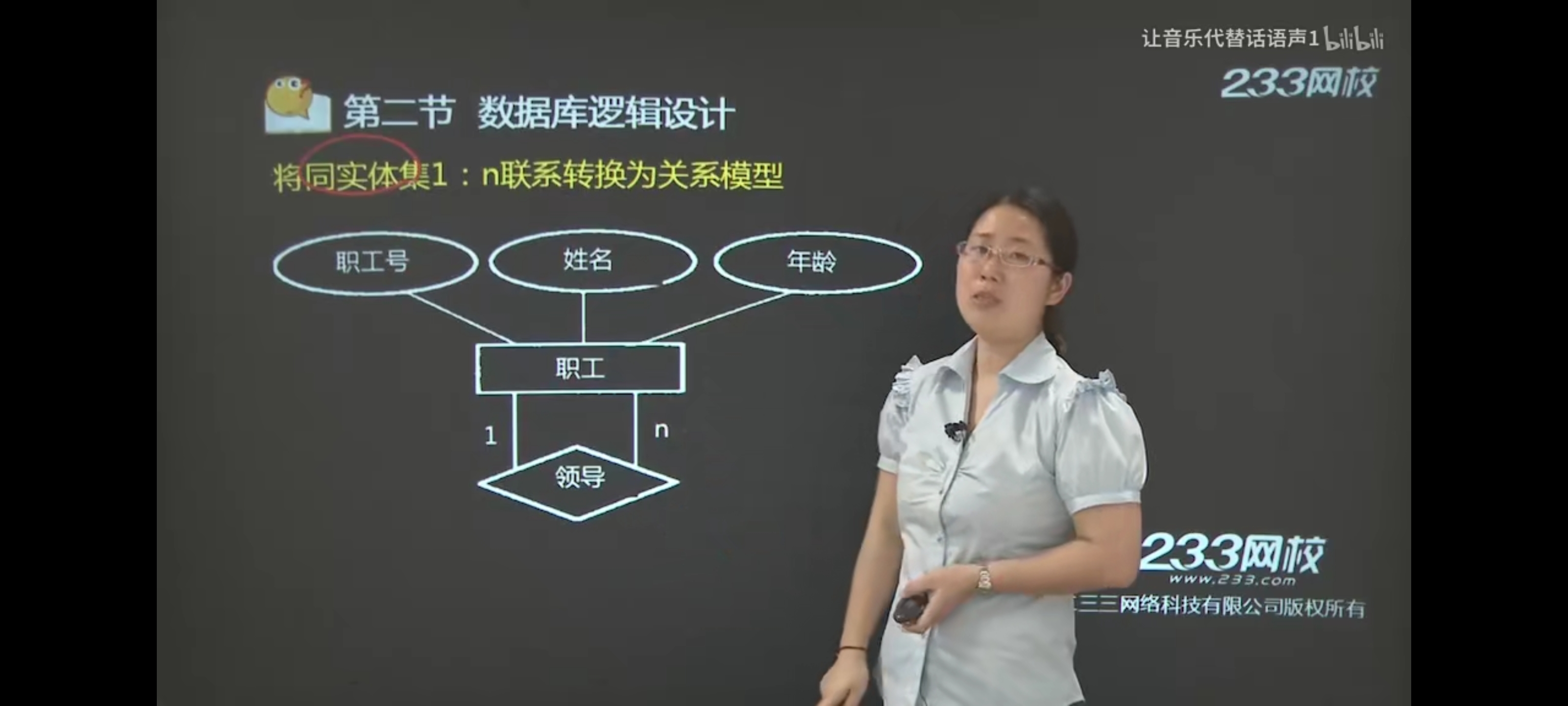
⑤同实体集1:n联系转换为关系模式

数据库物理设计是设计数据库的存储结构和物理实现方法。
目的:将数据的逻辑描述转换为技术规范,设计数据存储方案以便提供足够的好的性能以便确保数据库数据的完整性、安全性、可靠性
2、数据库的物理结构 一)①物理设备上的存储结构与存取方法称为数据库的物理结构;②数据库中的数据一文件形式存储在外存储介质上。
二)数据库的物理结构设计需要解决的问题:文件组织、文件结构、文件存取、索引技术
3、索引——数据库持久化设计(数据的存取) 1)①索引是数据库中独立的存储结构其作用是提供一种无须扫描每个页面(存储表格数据的物理块)而快速访问数据页的方案。 ②索引技术(Indexing)是一种快速数据访问技术
③索引技术的关键:建立记录域取值到记录的物理地址间的映射关系,即索引。
④索引能够提高性能(减少时间),但是需要付出额外的空间、在维护时也需要付出多余的时间
2)索引技术的分类
有序索引:又分为聚集索引和非聚集索引、稠密索引和稀疏索引;散列索引(哈希表存储);主索引;唯一索引、单层索引和多层索引
3)数据库的物理设计
目标:略;
环节:(1)数据库逻辑模式描述(关系模式-基本表);(2)文件组织与存取设计(基本原则:①将易变部分与稳定部分、存储频率较高的部分与存储频率较低的部分分开存放,以提高系统性能;②分析理解数据库事务访问特性);(3)数据分布设计(分布式数据库系统的数据划分:垂直划分和水平划分(各自的含义));(4)确定系统配置;(5)物理模式评估(对数据库的**时间和空间(存取时间、存储空间)**的效率进行评估)
3)什么是存取路径
选择存取路径主要是指确定如何建立索引。对同一个关系我们要建立多条索引路径。
4)DBMS常用的存取方法:索引方法(B+树索引方法)、聚簇方法、HASH方法
第三章 例题讲解1)

2)

3)

4)

5)

6)重点:第三章出现的设计与应用题




总述:DBAS功能设计包括应用软件设计中的数据库事务设计和应用程序设计。
功能设计过程分为:总体设计、概念设计、详细设计;具体到数据库事务设计分为:事物概要设计、事物详细设计
第一节 软件体系结构与设计过程 一、软件体系结构与设计过程一)软件体系结构:又称为软件架构是软件系统中最本质的东西,良好的软件体系结构必须是普适、高效和稳定的;软件体系结构={构件(软件系统的各个模块),连接件(接口和过程调用)、约束(完整性约束和规则)}
软件体系结构类型:分层体系结构、MVC(模型-视图-控制器)体系结构、客户端/服务器(B/S、C/S)体系结构
二)软件设计过程
1)软件开发有设计、实现、测试三个环节组成;包含概要设计(任务:软件总体结构图设计)和详细设计(任务:数据设计、过程设计及人机界面设计)
2)设计原则:模块化、信息隐藏、抽象和逐步求精
3)软件设计可选用的方法:结构化设计方法、面向对象方法、面向数据设计方法
第二节 DBAS整体设计DBAS整体设计的任务:确定系统整体框架;涉及的内容包括:DBAS体系结构设计、软件体系结构设计、软件硬选型与配置设计、业务规则初步设计
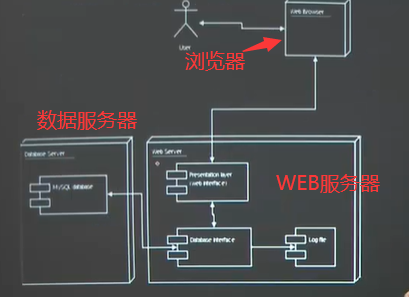
一、DBAS体系结构设计1)常见的DBAS体系结构:客户服务器体系结构(C/S)、浏览器服务器体系结构(B/S)
2)三层客户服务器体系结构(C/S):表示层、功能层(业务:应用服务器)、数据层(DB:数据库服务器)
二、软件体系结构设计1)DBAS软件包括:操作系统、数据库管理系统、开发环境中间件、应用软件(数据库事务和应用程序)
2)可用模块结构图(模块+调用+控制+转接)表示总体结构和分层模块结构(体系结构的情况)
三、软件硬选型与配置设计总体设计阶段需要对软硬件设备做出合理选择,并进行初步配置设计。
四、业务规则初步设计关键:业务流程图——总体设计阶段
第三节 DBAS功能概要设计1) DBAS功能概要设计在总体设计的基础上进一步细化模块/子模块,组成应用软件的系统—子系统—模块—子模块结构,并从结构、行为、数据三方面进行设计。
2)从功能角度,DBAS系统通常划分为四个层次:表示层、业务逻辑层、数据访问层、数据持久层
一、表示层概要设计1)人机界面设计,影响系统易用性(目前第四代为WIMP与web技术多任务处理技术相结合)
2)设计原则:对用户友好;用户自主控制;反馈及时上下文感知;容错与错误恢复;界面标准常规;输入灵活;界面简洁、交互及时。
二、业务逻辑层概要设计1)设计原则:高内聚低耦合
2)设计内容:结构、行为、数据、接口等等
三、数据访问层概要设计1)事物概要设计核心:在于辨识和设计事物自身的处理逻辑、注意流程
2)一个完整的事物概要设计包括:事务名称、访问的关系表和数据项、事务逻辑、事务用户
四、事务1)事务的概念(Transaction):事务是访问并可能更新数据库中各种数据项的一个程序执行单元
2)事务的特性:原子性、一致性、隔离性、持续性;称为ACID特性
原子性:一个不可分割的工作单位;一致性:从一个一致性状态变到另一个一致性状态;隔离性:执行不能被其他事务干扰;持久性:永久性,他对数据库的改变是永久的。
五、数据持久层概要设计第三章内容
第四节 DBAS功能详细设计 一、表示层详细设计人机界面采用原型迭代法。
二、业务逻辑层详细设计1)设计各模块内部处理流程和算法、具体数据结构和详细接口。
第五节 应用系统安全架构设计 一、数据安全设计安全性保护、完整性保护、并发性保护、数据备份与恢复、数据加密传输
1)数据库的安全性保护
(1)主要保护方法:用身份鉴别、权限控制
2)数据库的完整性保护
定义:数据库的完整性保护是指数据库中的正确性、一致性
及相容性
方法:设置完整性检查(即对数据设置一些约束条件(实体完整性、参考完整性、用户自定义完整性))
完整性条件作用对象:列、元组、关系
DBAS中的完整性约束功能包括:完整性约束条件设置和检查。
3)数据库的并发控制
并发控制:事务在空间上重叠执行。
并发控制机制是衡量一个DBAS性能的一个重要标志;实现并发控制常用的方法是封锁技术(就是Java里面的锁)。
基本锁类型:排他锁(X锁)—写锁、共享锁(S锁)—读锁
死锁:是两个或者两个以上的事务之间的循环等待。
避免死锁的原则: ①按照同一顺序访问资源。(如第一个事务提交或回滚后第二个事务进行) ②避免事务交互性 ③采用小事务模 式,缩短长度和占用时间。 ④尽量使用记录级别的所(行锁),少用表级别锁。 ⑤使用绑定连接,同一用户打开的两个或多个连接 可以互相合作。
4)数据的备份与恢复
数据库恢复的基本原理:
数据库备份与恢复的策略:双机热备、数据转储(数据备份)、数据加密存储(针对高敏感数据)
7)数据加密传输常见的传输手段:数字安全证书、对称密钥加密、数字签名、数字信封
二、环境安全设计漏洞与补丁、计算机病毒防护、网络环境安全(防火墙)、物理环境安全
三、制度安全设计管理层安全措施
第六节 DBAS实施 一、DBAS实施工作1)创建数据库、2)数据装载、3)编写调试应用程序、4)数据库系统运行(功能测试、性能测试)
第四章 例题1、

2)

3)

4)

5)

6)

7)

8)

内容摘要:
①了解DBAS建模方法;②掌握DBAS业务流程与需求表达方法;③掌握DBAS系统内部结构的表达方法;④掌握DBAS微观设计的表达方法;⑤了解DBAS宏观设计的表达方法;⑥了解DBAS系统实现与部署的表达方法。
第一节 DBAS建模 一、统一建模语言(UML)1)UML是面向对象的可视化的通用语言,他是一种建模语言不是建模方法。
2)建模方法包括建模语言与建模过程;①建模语言:提供这种方法用于表示建模结果的符号(图形符号:可视化);②建模过程:吗iOS建模时需要遵循的步骤。
二、UML的组成1)由**语义(自然语言)与表示法(可视化标准符号)**组成。
四层建模概念框架:元元模型、元模型、模型层(类模型或类型模型)、用户模型(实例模型:具体的对象)
2)UML的五种视图:结构、实现、行为、环境、用例视图
3)UML 2.0分为静态结构图和行为图
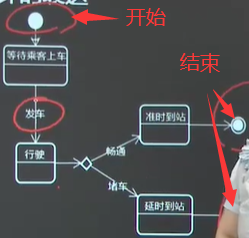
第二节 DBAS业务流程图与需求表达 一、业务流程与活动图 活动图最适合描述系统或子系统的工作流程。


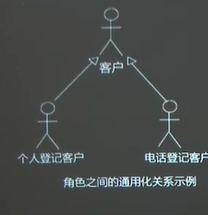
1)角色之间的关系——通用化关系(继承:extends)带三角符号的箭头
2)用例与角色之间的关系——连接关系(关联关系)
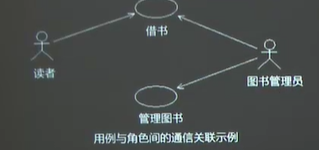
3)用例之间的关系——扩展(extends)关系、包含(use、include)(使用)关系、组合(关联)关系、泛化关系

1)类与类的关系:关联关系、继承、依赖、精化(实现)
2)组成:类名、属性、方法(操作、行为)

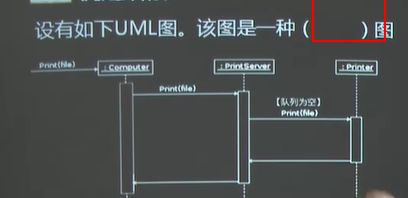
1)顺序图主要用于描述系统内对象之间的消息发送和接收序列;
2)顺序图中出现的元素一定是在类图中出现的;用来强调时间。



对象图是类图的实例,描述特定时间中所有对象在系统中的结构,是一个快照
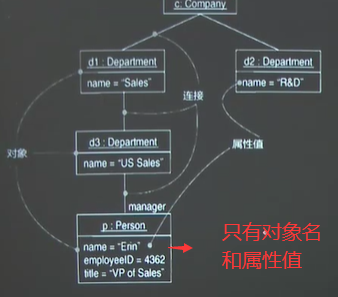
矩形框上面的左边为对象名——后面为所属的类
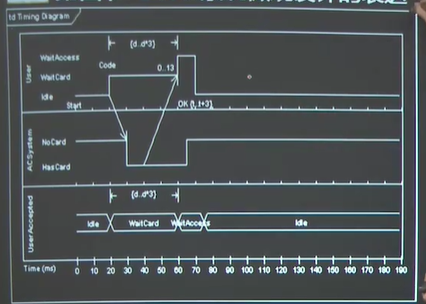
二、状态图1)状态图用来描述有关事件或对像的状态转移;只能有一个开始状态可以有多个结束状态。
2)状态图的转移由事件驱动。
当状态的转换由时间因素决定时,使用时间图来描述状态的变化。
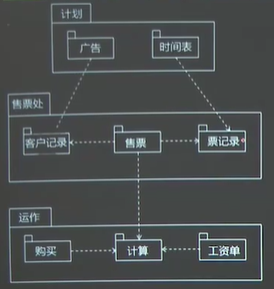
一、包图
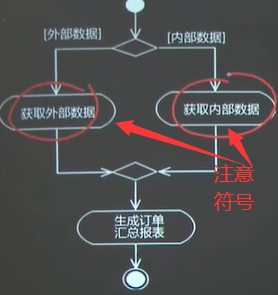
交互概述图相当于活动图和顺序图的结合
复合结构图适用于系统间的沟通接口,进行系统架构设计和系统维护时。
组件时逻辑中定义的概念和概念在物理架构中的实现。
1)描述系统中软硬件的物理配置情况与系统结构。
2)部署图说明实体组件如何执行程序,将如何部署到实际的计算机中——在集成测试之前。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EZPS9LIT-1616819653259)( ]
]
1)

2)

3)

4)

5)

6)
7)

1)系统数据库(系统自动创建):master、msdb、tempdb、model、resource
2)用户数据库
二、SQL server数据库的组成1)SQL server将数据库映射为一组操作系统文件。
2)数据文件:①.mdf:主要数据文件,不能小于3M。只有一个;②.ndf:次要数据文件,0个或多个;
日志文件:.ldf:事务日志文件,至少有一个日志文件。
三、数据库存储空间的发分配1)数据存储的最小单位是数据页(也就是页),一页是一块8KB的连续磁盘空间。
2**)页的大小决定了数据库表中一行**(一个记录、元组)数据的最大值—不能超过8KB
3)行不能跨页存储,一页可以存放多行数据但是不能超过8KB

1)类型:主文件组(系统定义,主要数据文件和如何没有明确分配的其他文件)、用户定义文件组(使用FILEGROUP关键字定义)

1)通过图形可视化工具直接创建
2)通过T-SQL语言创建


举例:





一)分离数据库
1)作用:就是将数据库从一台数据库服务器转移到另一台数据库服务器,不需要重建(类似于剪切)
2)使用的语句:sp_detach_db实现系统存储过程
二)附加数据库
将分离的数据库重新安装到数据库管理系统中,必须指定主要数据文件的物理存储位置和文件名。
2)语句:CREATE DATABASE …(数据库名) ON(存储位置) FOR ATTACH
第二节 架构 一、架构(模式)1)架构是数据库下的一个逻辑命名空间,是数据库对象的容器,一个数据库包含一个或多个架构,同一个数据库内架构命名唯一
2)定义架构语句:CREATE SCHEMA [] AUTHORIZATION []
3)删除架构:DROP SCHEMA []
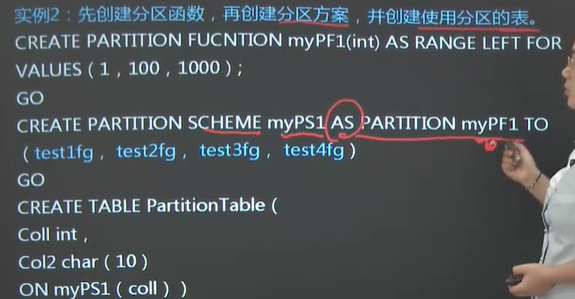
第三节 分区表 一、基本概念 1)分区表是将表中的数据按水平分割成不同的子集,并将数据子集存储在数据库一个或多个文件组中。
2)物理上将大表分成好几个小表,逻辑上还是一个大表;合理使用分区能提高数据库性能。
二、创建分区表
实例:

1)创建索引

2)删除索引

1)标准视图(也称虚拟表):返回结果集与标准表一致,标准视图的结果集不永久存放。
2)索引视图(也称物化视图):建立唯一聚集索引的视图;视图结果存放在数据库中。
二、索引视图使用与限制1)适用场合:①很少更新的基础数据;②基础数据使用批处理定期更新且作为只读数据
2)

创建索引视图必须满足的条件:①视图只能引用基本表,不能是其他的视图;②引用的基本表和视图在同一歌数据库中;③必须用SCHEMABINDING选项创建视图;④视图中的表达式引用的所有函数必须确定。
第六章例题1)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h5AUySgD-1616819653276)(C:\Users\潘仕毅\AppData\Roaming\Typora\typora-user-images\image-20210224184633675.png)]
2)

3)

4)创建唯一约束后面必须要字段

5)





6)


注意:在数据库设计题有怎么创建数据库
第七章 高级数据库查询 第一节 数据查询功能扩展 一、查询语句–SELETE(具体看荣莹数据库-第五章)1)SELETE语句的格式和含义
SELECT [DISTINCT] [TOP n] select_list ——查询指定的列、DISTINCT消除重复元组
[INTO new_table]——将查询结果创建到新表
[FROM table_source]——查询的目标表
[WHERE search_conditition]——查询的条件
[GROUP BY group_by_expression]——指定分组查询的条件
[HAVING search_condition]——指定组或聚合函数查询的条件
[ORDER BY order_expression [ASC|DESC]]——指定表的数据的升降序
[COMPUTE expression] ——在结果集得到末尾生成汇总数据
2)WHERE 条件表达式中可使用下列运算符:
Ø算术比较运算符:<、<=、>、>=、=、<>或!=。
Ø逻辑运算符:AND、OR、NOT(AND和 OR来联结多个查询条件可多次出现、 AND的优先级高于OR、 可以用括号改变优先级)。
Ø集合运算符:IN(DNAME IN ( ‘计算机’,‘电子’)表示取DNAME为’计算机’,’电子‘的结果集)、NOT IN(与前面相反)。
Ø谓词:EXISTS(存在量词)、ALL、SOME、UNIQUE(并)、BETWEEN … AND(在某个范围)、NOT BETWEEN … AND(不在这个范围) 。
Ø聚合函数:AVG、MIN、MAX、SUM、COUNT。
Ø F中运算对象还可以是另一个SELECT语句,即SELECT语句可以嵌套。
二、使用TOP限制结果集1)TOP n [percent] [WITH TIES]
• Top n 前n行
• Top n [percent]前n%行
• [WITH TIES]:包括最后一行取值并列的结果。
2)TOP的使用:SELECT TOP 3 WITH TIES 。。。。
三、使用CASE函数1)语法:
CASE
WHEN 布尔表达式1 then 结果表达式1
WHEN 布尔表达式2 then 结果表达式2
……
WHEN 布尔表达式n then 结果表达式n
[ELSE 结果表达式n+1]
2)使用举例
SELECT a.GoodsID,商品销售类别=CASE
WHEN COUNT(b.GoodsID)>10 THEN ‘热门商品’
WHEN COUNT(b.GoodsID)BETWEEN 5 AND 10 THEN ‘一般商品’
WHEN COUNT(b.GoodsID)BETWEEN 1 AND 4 THEN ‘难销商品’
ELSE ‘滞销商品’
END
FROM Table_Goods a LEFT JOIN Table_SaleBillDetail b
ON a.GoodsID=b.GoodsID GROUP BY a.GoodsID
四、将查询结果保存到新表中SELECT 查询列表序列 INTO
FROM 数据源……(其他行过滤、分组语句)
注意:表名前加**#为局部临时表,##为全局临时表**,只有表名为永久表。
例子:SELECT * INTO #HD_Customer FROM Table_Customer WHERE ……
注意:局部临时表和全局临时表只在当前查询中一次有效
第二节 查询结果的交、并、差运算①在FROM子句中给出多个表名,即可完成笛卡尔积运算。
②建立几个表连接的方法:在FROM子句中列出需连接的表名,在WHERE子句给出连接条件或连接谓词
一、并运算1)并运算(UNION):将多个查询结果合并为一个结果集。。
语法:
SELECT 语句1 UNION [ALL]SELECT 语句2 UNION [ALL]2)使用UNION注意:
Ø要进行合并的查询,SELECT中列数必须相同,语义相同。
Ø每个相对应列的数据类型隐式兼容,如char(20)与varchar(40)。
Ø合并后结果采用第一个SELECT语句的列标题。
Ø若需排序,则GROUP BY语句写在最后一个SELECT之后,且排序的一句是第一个SELECT中的列名。
3)举例:求选修了课程C2或C4的学生的学号和姓名
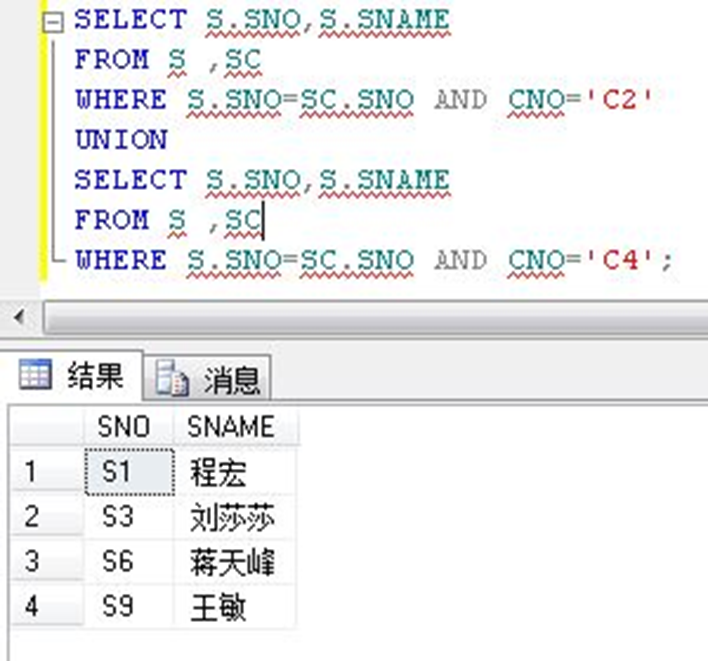
1)交运算:返回同时在两个集合中出现的记录。
语法:
SELECT 语句1INTERSECT SELECT 语句2INTERSECT ……SELECT 语句n2)举例:求选修了课程C2和C4的学生的学号和姓名
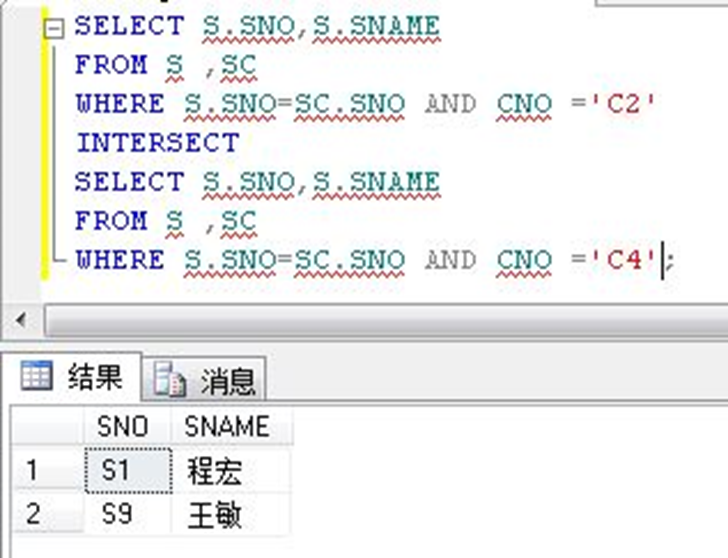
1)差运算:返回第一个集合中有而第二个集合中没有的的记录。
语法:
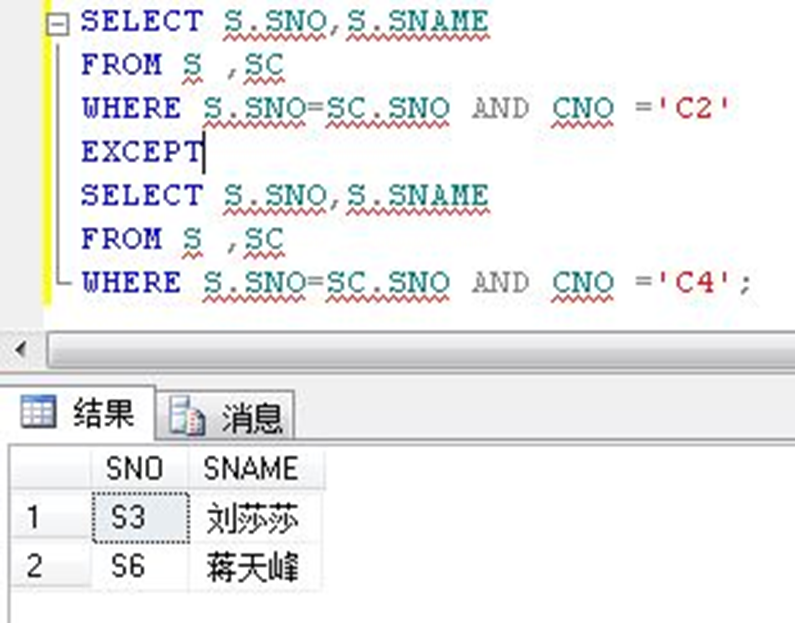
SELECT 语句1EXCEPT SELECT 语句2EXCEPT……SELECT 语句n2)举例:求选修了课程C2但没有选修课程C4的学生的学号和姓名
1)WHERE子句中的条件表达式可以是标量数据 ,也可以是一个SELECT-FROM-WHERE查询块构成的子查询。
SELECT /*外层查询 /父查询*/ FROMWHERE (SELECT /*内层查询/子查询*/FROM WHERE)2)①子查询的限制:不能使用ORDER BY子句;②层层嵌套方式反映了 SQL语言的结构化,③有些嵌套查询可以用连接运算替代
3)举例:求选修了数据结构的学生的学号
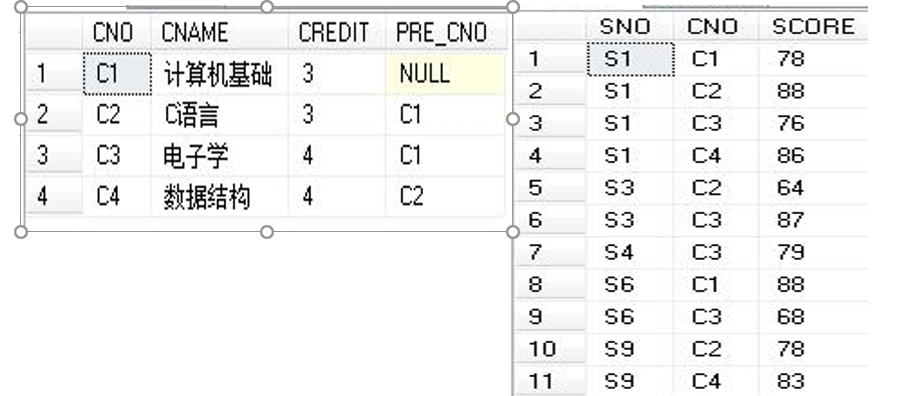
SELECT语句:
SELECT SNO FROM SC WHERE CNO = (SELECT CNO //子查询语句返回的结果集要与父查询语句的条件的名称(语义)相同,但是为不同的表 FROM C WHERE CNAME= ' 数据结构‘);也可以用自身连接完成前例查询要求
SELECT SNOFROM SC, CWHERE SC.CNO = C.CNO AND C.CNAME= '数据结构'; 二、包含多值的子查询1)子查询的结果不是单一值,而是多个值,即一个集合(记为R)。与子查询结果比较,可使用以下运算符:
① EXISTS R是一个条件,当且仅当R非空时,该条件为真。
EXISTS相当于离散数学中的存在量词。
② s IN R为真,当且仅当s等于R中的一个值。类似地,s NOT IN R为真,当且仅当s不等于R中的值。
IN的含义相当于集合论中的“属于”(∈)。类似地,s NOT IN R,表示s不属于R。
③ s>ALL R为真,当且仅当s大于关系R中的每一个值。同样可以使用其他五个比较运算符(>=、=、=、=、 ANY 大于子查询结果中的某个值 (存在大于)
> ALL 大于子查询结果中的所有值(比最大值还大)
< ANY 小于子查询结果中的某个值 (存在小于)
< ALL 小于子查询结果中的所有值 (比最小值还小)
>= ANY 大于等于子查询结果中的某个值 (存在大于或等于)
>= ALL 大于等于子查询结果中的所有值 (应该为一个与子查询相同大小的集合)
42000;-----步骤③
having子句使用 having avg_salary 会有什么不同?
任何出现在having子句中,但没有被聚集的属性必须出现在 group by 子句中,否则查询就被当成错误的。
包含聚集、group by或having子句的查询包含聚集、group by或having子句的查询的含义可通过下述操作序列来定义:
最先根据 from 子句计算出一个关系;如果出现 where 子句, where 子句 中的谓词将应用到 from子句 的结果关系上;如果出现了group by 子句, ①满足 where 谓词的元组通过group by 子句形成分组。 ②如果没有 group by 子句,满足where谓词的整个元组集被当做一个分组。如果出现了 having子句,它将应用到每个分组上;不满足having子句谓词的分组将被抛弃。select 子句 利用剩下的分组产生出查询结果中的元组,即在每个分组上应用聚集函数来得到单个结果元组。 查询10.同时使用having和where子句“对于在2009年将受的每个课程段,如果该课程段至少2名学生选课,找出选修该课程段的所有学生的总学分(tot_cred)的平均值”。student(ID, name, dept_name, tot_cred)takes(ID, course_id, sec_id, semester, year, grade)select course_id, sec_id, semester,year,avg(tot_cred) //⑤对大表进行分割,返回的结果集from takes natural join student //①自然连接where year = 2009 //②该条件先确定了时间段为2009年group by course_id,semester,year,sec_id //③找出了2009年段的数据后根据 course_id,semester,year,sec_id 分组having count(ID) >= 2; //④对分组的数据进行选择对空值和布尔值的聚集
四、聚集函数处理空值规则如下: 除了count(*) 外的所有聚集函数都忽略输入集合中的空值;空值被忽略有可能造成参加函数运算的输入值集合为空。规定空集的count运算值为0 ;其他所有聚集运算在输入为空集的情况下返回一个空值。 SQL:1999 中 引入了布尔数据类型,可以取true, false, unknown 三个值。有两个聚集函数some 和 every。
开窗函数原文