倒计时10天,300万人的命运的齿轮即将转动。
下周,也就是11月26日,国考笔试正式开考。在一系列社会和经济背景交织下,这次国考人数逼近300万,创历史新高。其中,31万人在审核环节被刷下,能够走进考场的261万人,最终也只有3.96万人有机会可以成功上岸,超过98%的考生沦为炮灰。
围绕大模型考公话题,Yuri用一套国考行测模拟题对12家国产大模型做了测试,其中6家总体正确率65%以下,按照以往国考笔试分数,一般行测题65分以上有进入面试可能。这就是说,一半国产大模型参加考公失败。这其中包括被视为中国最像OpenAI的大模型创业团队智谱AI、腾讯混元大模型以及高调宣布将在2024年上半年全面对标GPT-4的讯飞星火大模型。
最大跌眼镜的是腾讯推出混元大模型,总体正确率34%,排名倒是第一。这样的结果和大厂的身份着实不符,估计鹅厂不擅长小镇做题家吧。
大超预期的是文心一言,在上个月发布的文心一言4.0能力相比此前有明显提升,在这次国考模拟行测题中连对18道!虽然很多人觉得百度不行了,但是百度在AI这块确实在下功夫做事的。
政治意识较强的是360智脑,为了安全,不少问题主动放弃了作答。
宇宙厂字节跳动的豆包大模型,在这次模拟测试中拿下数学分类第一。总体正确率70%以上,基本上可以顺利通过笔试。
以下是大模型考公详细评测内容,AI新智界经作者Yuri授权整理发布。Yuri现任某科技企业AI市场战略,主要关注AI相关的技术进展、行业动态和商业化的情况。
01、测试缘由
上周在群里看到有朋友问国内哪个大模型可以做公考、行测题,于是心血来潮求了一份题目,花了一周左右的时间完成测试,主打图一乐。
提前说明:本测试结果没有任何地缘和公司立场,单从一个用户体验角度评论,仅表示模型在所测题目及同类题目的任务表现,并不能完全代表模型在其他任务上的能力和表现,大家做的是AI大模型、不是做题家,也许这次测试正确的题再测一次也会错误,一次测试结果并不能说明什么,水淹七军了最后也会走麦城,端平入洛收复两京最后还是崖山殉国,省模考了前三最后高考也可能只能去财大。OpenAI在灯塔尖,我们在长城内,大家都有光明的前途呐。
20231115更新:感谢Will在第二张sheet最后一列新增了GPT-4 Turbo(未联网)的测试结果,总体正确率为73.7%。
02、测试题目及方法
使用的题集是群友提供的四海教育《2023下半年笔试套题冲刺班·一期 行政职业能力测验(三)》,从前面的110道题中刨除了需要识图判断的71-80题和83题,总共99道题。
测试采用首次生成的答案,人工不参与干预、没有重新生成的机会(实际测试的时候在第69题因为天工生成卡顿了两次但又实在想看它的结果是什么所以人工点了两次“继续生成”)。
测试提问方式基本上以“下面这道题选什么?”开头,在类比推理部分为了降低模型理解难度改为“下面这道类比推理题选什么?”开头。
03、测试结果
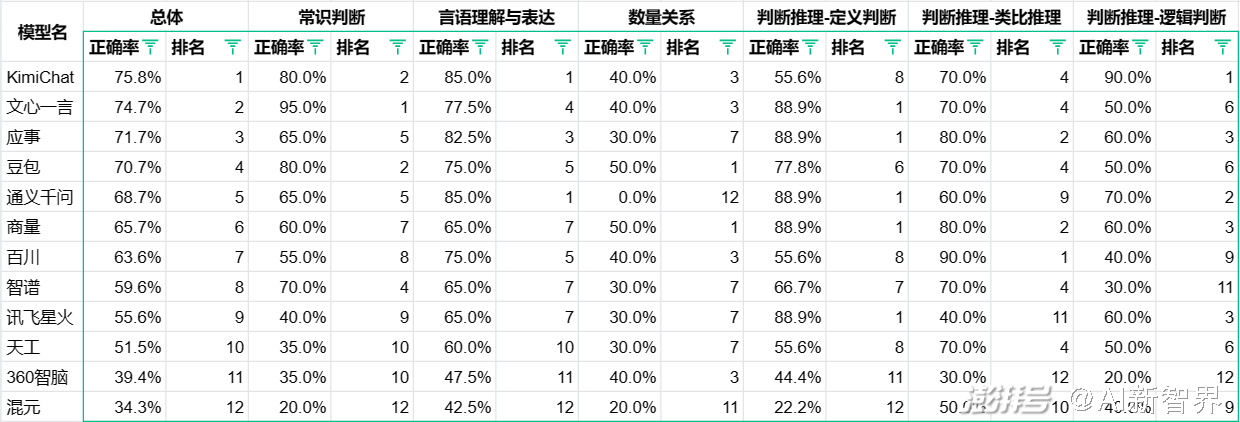
12款国产大模型国考模拟行测题正确率
各模型测试正确率雷达图
文心一言
①文心4.0更新之后的效果确实非常超乎预期,尤其是前面18连对的时候,感叹能力确实相较文心3.5提高非常多,看来今年从3.0到3.5再到4.0确实是下了不少功夫的。
②文心也是此次测试中少有的能够不需要开启新对话全部完成作答的模型之一(另外两个是豆包和应事)。
③文心在文本类的任务上回答速度挺快的,基本上能够做到提问后1-2秒就开始作答,且不需要让页面停留在文心的网页还会继续作答,但是在数量关系和计算问题的时候反应就会变慢,其中有一道题甚至思考了20s左右才开始答题,差点以为要翻车(虽然还是答错了),到后面问更长段的文本问题文心也会出现跳转页面回来之后还在生成的情况,不知道是不是对长文本和数学题一样还需要