虽然医学 LLM 应用前景广阔,模型的评估仍有许多挑战,在医院中部署 LLM 会带来重大的伦理问题,使得实际反馈变得困难。现有的模型评价通常使用自动评估(GPT-4),考虑到医疗的准确性和专业性要求,这种没有参考答案的评估欠缺说服力。而专业的人工评判昂贵而不易扩大规模。
BioLAMA 拥有参考答案,但它是为了评估掩码语言模型而不是自回归模型。MultiMedBench 包括问题解答、报告总结、视觉问题回答、报告生成和医疗图像分类,但 MultiMedBench 只有英文版本,直接翻译一方面需要对中英文医学和文化有深入了解,另一方面难以覆盖中医医学知识。
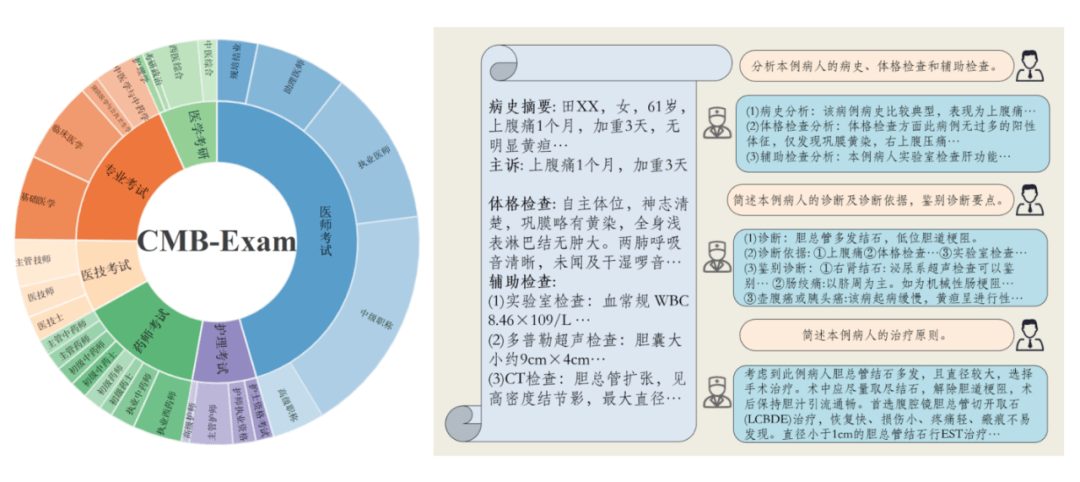
为此,我们提出了中文医疗模型评估基准 CMB,其包括了不同临床职业、不同职业阶段考试中的多项选择题(CMB-Exam)和基于真实病例的复杂临床诊断问题(CMB-Clin)。通过测评实验,我们发现:(1)GPT-4 在医学领域表现出显著优越性,于此同时中文通用大模型也表现得相当出色;(2)医疗大模型在性能方面仍然落后于通用模型,还有很大的提升空间(3)有参考答案和评分标准的问诊自动评估与专家评估高度对齐,提供了一个医学领域超级对齐的初步尝试。
数据集详细介绍
为了分别评测模型医疗知识掌握程度和临床问诊能力,我们分别构建了 CMB-Exam 和 CMB-Clin 集。
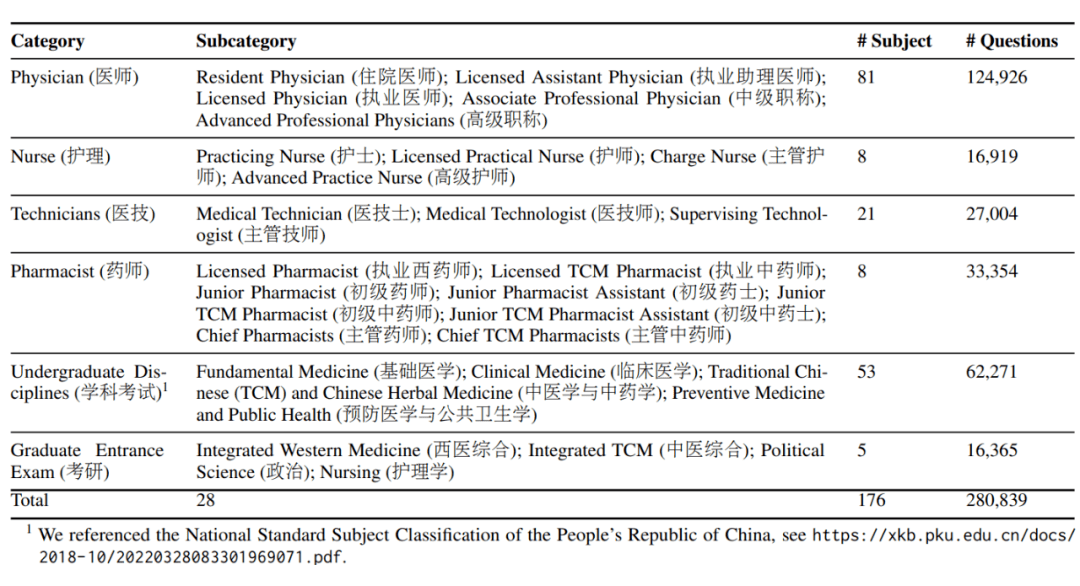
CMB-Exam 的构建理念是反映真实医疗领域的考核体系,覆盖了医生、药剂师、医技科室、护士岗位,对于一致的大学学科知识考试和研究生入学考试进行了合并,归纳出了六个类别。类别中依据职业阶段进行子目录的划定,子目录中又针对不同科室提供了细粒度更小的标签。
其数据的来源主要为历年真题、模拟题、课程练习题和章节测试题。其中一部分来自于医学题库网(https://www.medtiku.com/),获得了维护者的支持。为了确保数据质量,我们采用了一套规范的数据预处理流程,包括数据去重、清洗,针对原数据无法确认问题质量的地方,我们还进行了人工校验,纠正文法错误。同时,利用中国医疗试题库提供的评论系统,实行了严格的选题和删题过程,保证了问题中蕴含知识的准确度。
CMB-Clin 基于 74 个复杂真实案例,考察模型在真实诊断和治疗情境中的知识应用水平,评测其是否可以利用知识真正帮助解决临床复杂问题。其中,每个案例包含病历详情和 1~3 个问题,共 208 个问题。模型需要理解病人信息,包括主诉、病史概要、体格检查。根据这些信息来解答与诊断和治疗相关的问题,有些问题可能彼此关联。模型也需要能提供问题的解决方案。在与考官进行的对话模拟中,模型需要展现出其诊断和治疗能力。
实验结果和分析
我们选用了 7 个中文开源医疗模型(HuatuoGPT [1],BianQue-2 [2],ChatMed-Consult [3],MedicalGPT [4],ChatGLM-Med [5],Bentsao [7],DoctorGLM [6]),2 个中文通用模型(ChatGLM-2 [8],Baichuan-13B-Chat [9])以及 ChatGPT 和 GPT-4,在对齐超参的条件下,在 CMB-Exam 和 CMB-Clin 上对比他们的表现。
3.1 CMB-Exam实验
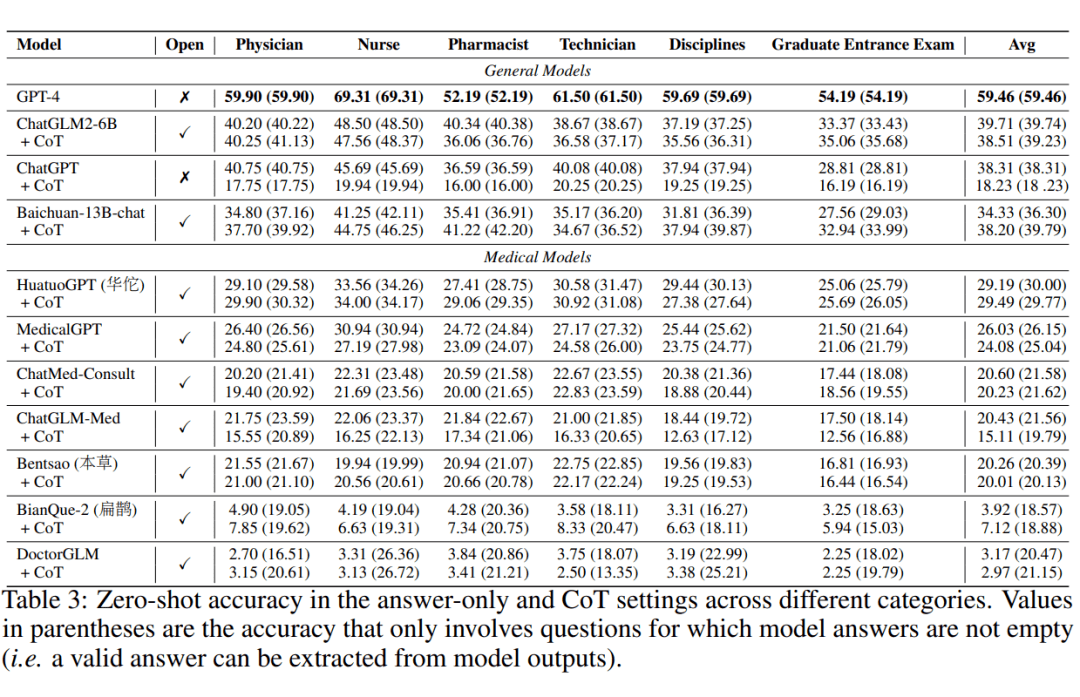
我们对比了 Zero-shot 条件下各模型的表现,在通用语言模型中,GPT-4 在医学领域的表现远超过其他模型,但仍然有很多问题回答错误。中文通用模型 ChatGLM2-6B 和 Baichuan-13B-chat 紧随 GPT-4 之后。值得一提的是,参数量仅为 6B 的 ChatGLM2 模型甚至超过了 ChatGPT,显示了国产大规模模型的快速迭代能力和专业知识领域的卓越表现。
在医疗领域的模型中,中文医疗模型的发展似乎落后于通用大型模型。其中,BianQue-2 [2]和 DoctorGLM 由于输入长度的限制和指令跟随能力的不足,使得无法在模型回答中抽取答案,导致了分数较低。
在不同临床职业的评分中,LLM在各个临床专业领域表现不一,如药剂师相关问题得分较低,而护士相关得分较高。这可能是因为护士需要的基础知识相对直接,而药剂师需要处理的药名和药效差别较大。尽管在专业领域中的表现存在差异,但模型表现出一致的趋势,不特别偏向特定职业。这些发现对于我们的研究和优化工作至关重要。
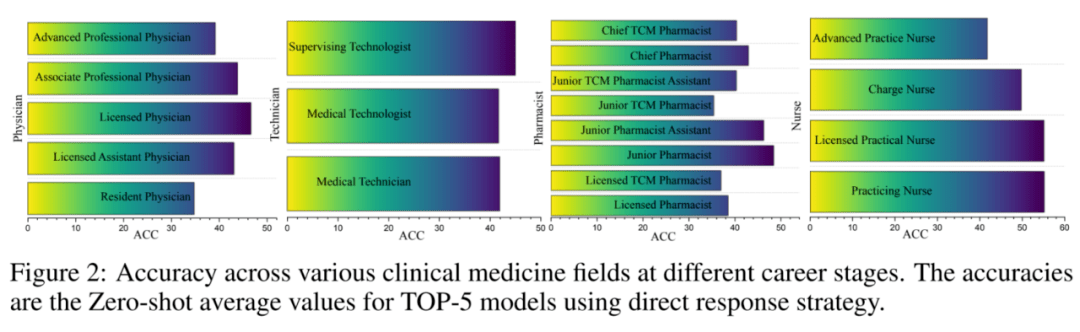
另外,研究还检验了 AI 模型和人类对考试难度感知上的一致性(Figure 2)。结果显示,医师和护士模型的准确率随着职业等级的提升而降低,但医学技术人员则呈现出相反的趋势,其主管技师考试的准确率最高。这可能是因为此类考试更侧重于人员管理和交流,而这并非医学专业的内容,而是可以从大量的通用语料库中学习的。而对于药师,我们发现涉及到传统医学的问题难度较大,这也说明了为中文医学领域开发大模型的必要性。
此外,我们还探索了 Few-shot 和 CoT 策略的效果,我们发现 CoT 并不总能提高模型的精度,可能其反而会给模型带来不相关的背景信息,妨碍了模型的推理能力。而 Few-shot prompting 策略在模型已经展现出较高准确性的情况下效果最明显。在表现欠佳的模型中,使用这种策略可能反而会损害模型的结果。后者的原因可能有两个:一是模型在处理大段输入时遇到困难,二是模型可能需要进一步的优化,以更好地利用上下文中的示例。
3.2 CMB-Clin实验
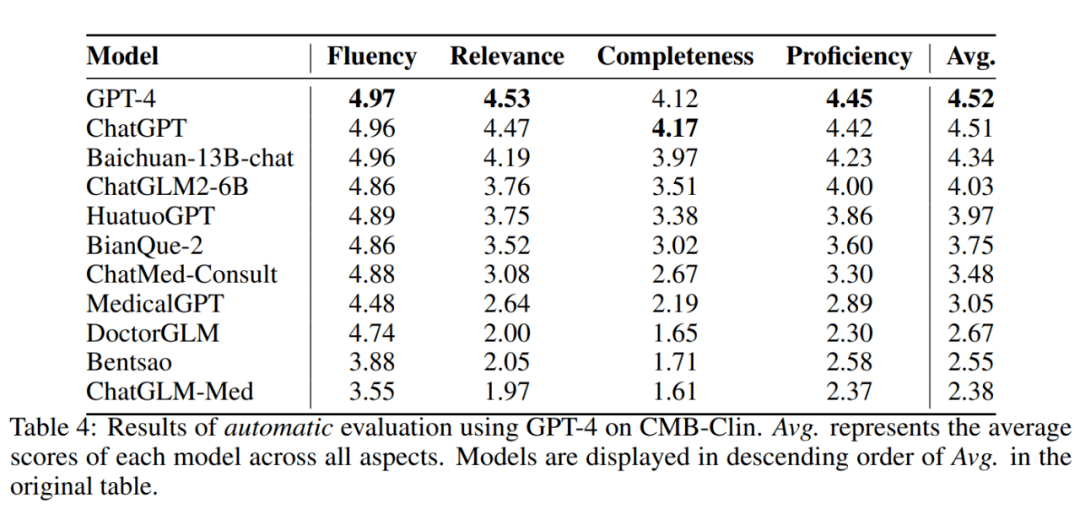
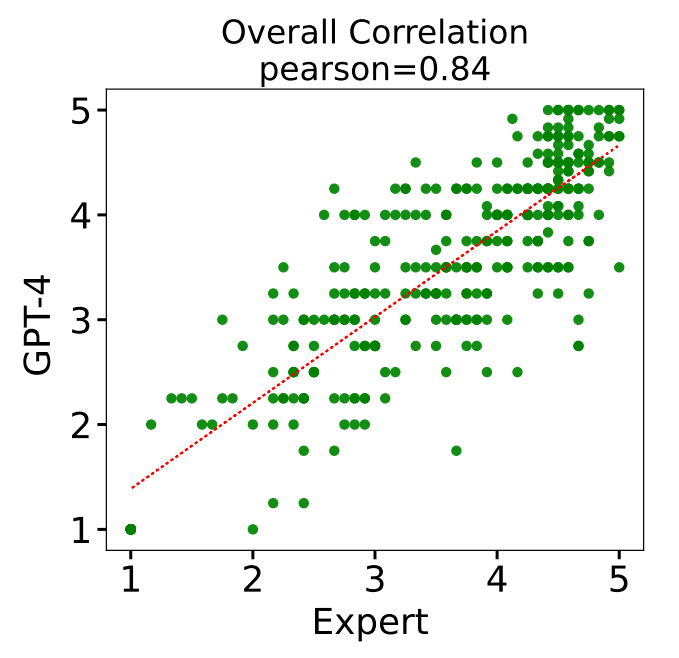
我们从四个维度(流畅性、相关性、完整性、医学知识专业性),用人工评估和自动评估的方式对语言模型在 CMB-Clin 评测数据集上的输出进行打分。上表是 GPT-4 基于参考答案和评分标准得出的模型分数。同时我们对自动评估和专家评估的一致性进行了量化统计,发现自动评估和专家评估之间的结果存在高度的一致性,两者的结果排名 Spearman 系数为 0.93(Figure 3),分数的 Pearson 系数为 0.84(Figure 4)。
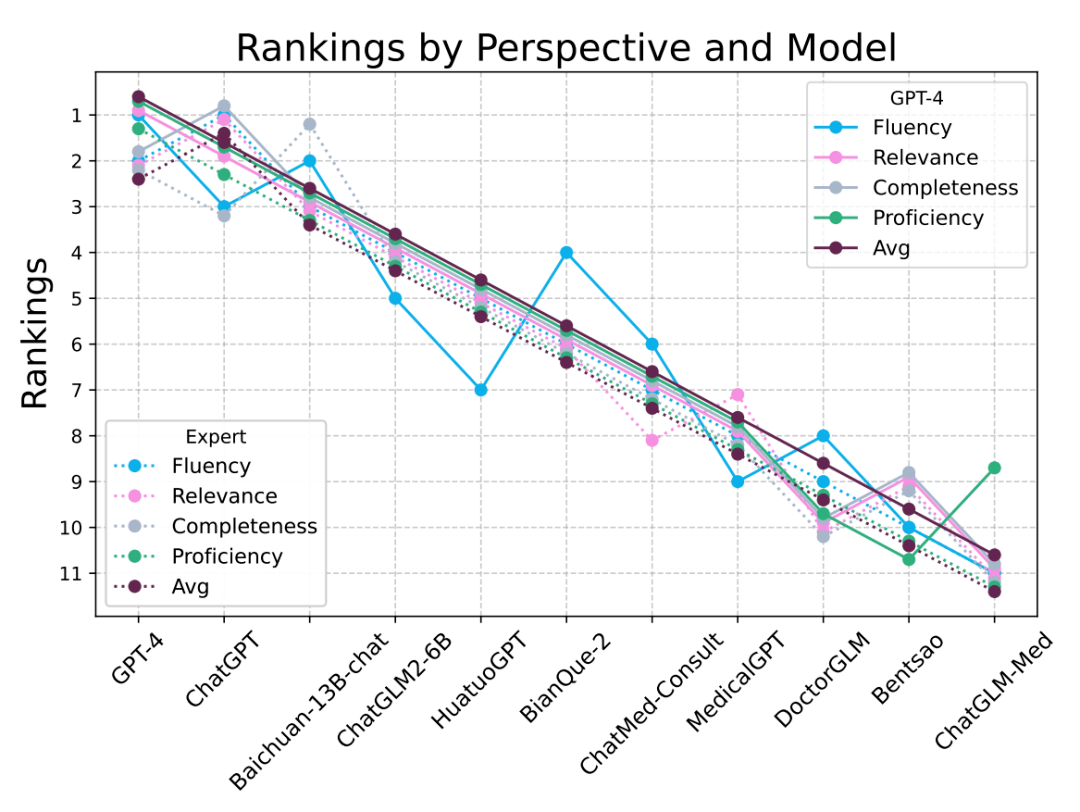
其次,CMB-Exam 和 CMB-Clin 两组数据的排名结果也非常一致,Spearman 系数达 0.89。我们希望模型在 CMB-Exam 的训练集上进行微调后,仍然能在 CMB-Clin 上获得不错的分数,与社区的期望进行对齐:既有足够的医学知识,有能和患者进行有效的交流帮助解决实际问题。
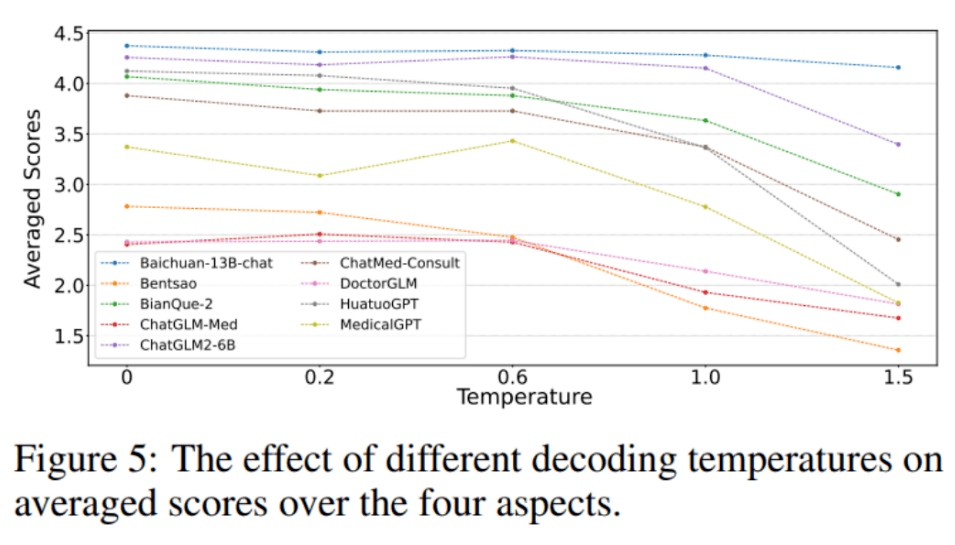
我们还探索了不同解码温度下的结果之间的差异。我们发现,当解码温度从 0 增加到 1.5 时,模型的整体表现有所下滑,这可能是因为较高的温度会导致输出的随机性(多样性)增加,而在医学领域,我们更偏好准确的内容。同时,我们也发现在不同的解码温度下,模型的排名结果的稳定性都非常高。
总结
CMB 从现实医学考核和临床应用出发,结合选择题和复杂病历问诊来全面检验模型在医学知识与诊断能力上的表现。我们真诚地希望,CMB 可以为医学大模型的研发者们提供有力的反馈,帮助更快地完善模型,促进中文医学领域语言模型的持续创新和应用。
相信在我们的共同努力下,未来医疗大模型的社会接受度和应用场景将不断扩大,为人口老龄化,医疗资源分配不均,医生超负荷工作和成长空间受限等问题,提供 AI 社区的缓解方案。
参考文献
[1] Hongbo Zhang, Junying Chen, Feng Jiang, Fei Yu, Zhihong Chen, Jianquan Li, Guiming Chen, Xiangbo Wu, Zhiyi Zhang, Qingying Xiao, et al. 2023a. Huatuogpt, towards taming language model to be a doctor. arXiv preprint arXiv:2305.15075
[2] Yirong Chen, Zhenyu Wang, Xiaofen Xing, Zhipei Xu, Kai Fang, Sihang Li, Junhong Wang, and Xiangmin Xu. 2023. Bianque-1.0: Improving the "question" ability of medical chat model through finetuning with hybrid instructions and multi-turn doctor qa datasets. Github.
[3] Chatmed: A chinese medical large language model. https://github.com/michael-wzhu/ChatMed.
[4] Medicalgpt: Training medical gpt model. https://github.com/shibing624/ MedicalGPT.
[5] Haochun Wang, Chi Liu, Sendong Zhao Zhao, Bing Qin, and Ting Liu. 2023b. Chatglm-med: 基于 中文医学知识的chatglm模型微调. https://github.com/SCIR-HI/Med-ChatGLM.
[6] Honglin Xiong, Sheng Wang, Yitao Zhu, Zihao Zhao, Yuxiao Liu, Qian Wang, and Dinggang Shen. 2023. Doctorglm: Fine-tuning your chinese doctor is not a herculean task. arXiv preprint arXiv:2304.01097
[7] Haochun Wang, Chi Liu, Nuwa Xi, Zewen Qiang, Sendong Zhao, Bing Qin, and Ting Liu. 2023a. Huatuo: Tuning llama model with chinese medical knowledge.
[8] Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. 2022. Glm: General language model pretraining with autoregressive blank infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 320–335.
[9] https://github.com/baichuan-inc/Baichuan-13B