1. 二叉树题目
略
2. 层序遍历算法题
1)由顶向下逐层访问
2)可以用队列存储树,每次打印根节点并将左右节点放进队列
(参考:https://www.cnblogs.com/masterlibin/p/5911298.html)
3. 图论中的最大团、连通分量,然后问图划分的算法
略
4. 如何判断社区活跃度(基于图),现在想着可能是根据连通分量吧
略。
5. 给定相邻两个节点的相似度,怎么计算该点到其它点的相似度
1)把这个问题看成多维尺度分析问题(MDS),那么实际上就是已知点之间的距离,构造一个空间Z,使得这个空间内点之间的距离尽可能保持接近。点在新空间Z中的向量化就是点的表示,然后点到点的距离就可以。
(MDS求解参考:https://blog.csdn.net/u010705209/article/details/53518772?utm_source=itdadao&utm_medium=referral)
2)其它:已知节点间距离,将节点embedding。这里我不太懂,希望大家有思路的可以指点下,谢啦
3)上诉两个答案也可能是我没看懂题意,因为该题的上下文是做复杂网络相关的研究。那么可能是知道任意两个相邻节点的相似度,求非相邻节点的相似度。这里可以参考simRank算法,即两个点的邻域越相似(有很多相似邻居),那么两个点越相似。有点像pageRank,是一个迭代的定义。
(参考:https://blog.csdn.net/luo123n/article/details/50212207)
6. 给一堆学生的成绩,将相同学生的所有成绩求平均值并排序,让我用我熟悉的语言,我就用了python的字典+sorted,面试官说不准用sort,然后问会别的排序,我就说了冒泡排序,原理我说了,然后问我还知道其他排序,答堆排序(其实我之前这方面复习了很多),之后问我有没有实现过(这个问题简直就是我的死角,就是没实现过,所以才想找个实习练练啊)
1)python直接pandas下groupby studentID sort
2)实现排序算法
7. 问了我机器学习熟悉的算法,答svm,讲一下原理
1)一种分类方法,找到一个分类的超平面,将正负例分离,并让分类间隔尽可能大
2)过程:
a. 线性svm:损失函数如下
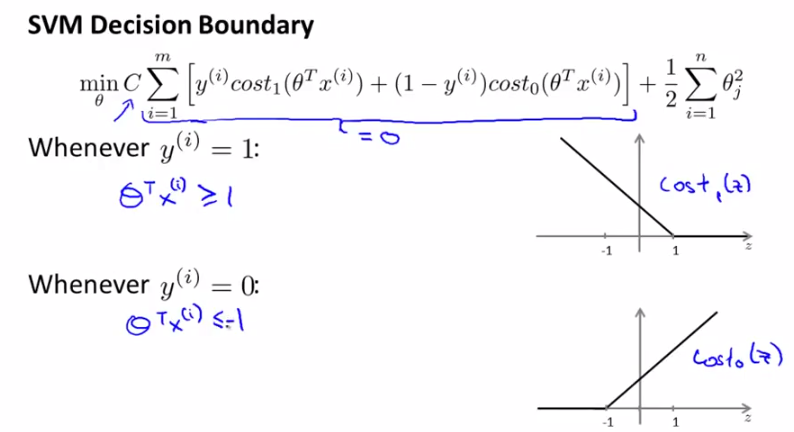
b. 对偶学习问题
c. 核函数:为了实现非线性分类,可以将样本映射到高维平面,然后用超平面分割。为了减少高维平面计算内积的操作,可以用一些“偷吃步”的方法同时进行高维映射和内积计算,就是核函数。包括多项式核函数、高斯核函数和sigmoid核函数
d. soft kernel
(参考林轩田《机器学习技法》,SVM这部分的推导讲得很清楚;或者参考https://blog.csdn.net/abcjennifer/article/details/7849812/)
3)优点:
a. 容易抓住特征和目标之间的非线性关系
b. 避免陷入局部解,泛化能力强
c. 可以解决小样本高维问题(如文本分类)
d. 分类时只用到了支持向量,泛化能力强
4)缺点:
a. 训练时的计算复杂度高
b. 核函数选择没有通用方案
c. 对缺失数据敏感
8. c中struct的对齐,我这个真的没听过,面试官让我之后自己查
为了提高存储器的访问效率,避免读一个成员数据访问多次存储器,操作系统对基本数据类型的合法地址做了限制,要求某种类型对象的地址必须是某个值K的整数倍(K=2或4或8)
1)Windows给出的对齐要求是:任何K(K=2或4或8)字节的基本对象的地址都必须是K的整数倍
2)Linux的对齐要求是:2字节类型的数据(如short)的起始地址必须是2的整数倍,而较大(int *,int double ,long)的数据类型的地址必须是4的整数倍
(参考:https://www.cnblogs.com/fengfenggirl/p/struct_align.html)
9. 机器学习被调数据分析了,因为做推荐的,所以面试一直在聊具体场景的推荐方法,其他方面知识没有怎么问
略。
10. 梯度下降和极大似然
1)梯度下降:
a. 是解决优化问题的一种方法,较适合于凸函数的优化,可以找到极值(极小值和极大值)
b. 对于某个参数,计算损失函数对该参数的偏导,该偏导即为下降方向。然后参数沿着该方向更新一个步长(学习率)
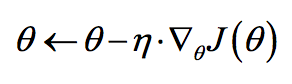
c. 迭代直到满足迭代次数或者参数不再变化
d. 包括梯度下降、随机梯度下降、mini-batch梯度下降
e. 只用到了一阶导信息,用牛顿法可以引入二阶导数信息
f. 梯度下降有效性的证明:用泰勒展开看

(参考:https://www.zhihu.com/question/24258023 @杨涛 的回答)
2)极大似然估计:
a. 思想:事件概率A与一个参数θ有关,我们观察到一系列事件,那么此时θ的取值应该是能使P(A|θ)最大的那个值。
b. 过程:
(1)写出似然函数
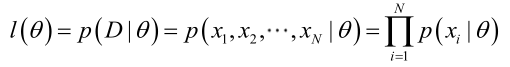
(2)我们求解的目标是使似然函数最大
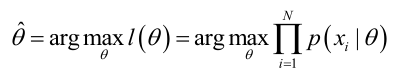
(3)因为是乘法问题,一般log化变成加法问题求解。即对要求的参数θ求偏导,令其为0
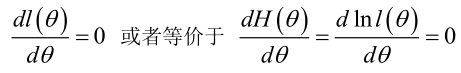
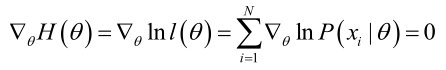
(参考:https://blog.csdn.net/zengxiantao1994/article/details/72787849)
11. 特征选择的方法
1)过滤:计算特征与标签之间的卡方、互信息、相关系数(只能识别线性关系),过滤掉取值较低的特征。或者使用树模型建模,通过树模型的importance进行选择(包括包外样本检验平均不纯度、特征使用次数等方法)
2)包裹:认为特征间的交叉也包含重要信息,因此计算特征子集的效果
3)嵌入法:L1正则化可以将不重要的特征降到0、树模型抽取特征
4)降维:PCA、LDA等
12. GBDT和xgboost,bagging和boosting
12.1 GBDT
1)首先介绍Adaboost Tree,是一种boosting的树集成方法。基本思路是依次训练多棵树,每棵树训练时对分错的样本进行加权。树模型中对样本的加权实际是对样本采样几率的加权,在进行有放回抽样时,分错的样本更有可能被抽到
2)GBDT是Adaboost Tree的改进,每棵树都是CART(分类回归树),树在叶节点输出的是一个数值,分类误差就是真实值减去叶节点的输出值,得到残差。GBDT要做的就是使用梯度下降的方法减少分类误差值
在GBDT的迭代中,假设我们前一轮迭代得到的强学习器是ft−1(x), 损失函数是L(y,ft−1(x)), 我们本轮迭代的目标是找到一个CART回归树模型的弱学习器ht(x),让本轮的损失损失L(y,ft(x)=L(y,ft−1(x)+ht(x))最小。也就是说,本轮迭代找到决策树,要让样本的损失尽量变得更小。
GBDT的思想可以用一个通俗的例子解释,假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。如果我们的迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小。
(参考:https://www.cnblogs.com/pinard/p/6140514.html)
3)得到多棵树后,根据每颗树的分类误差进行加权投票
12.2 xgboost
xgb也是一种梯度提升树,是gbdt高效实现,差异是:
1)gbdt优化时只用到了一阶导数信息,xgb对代价函数做了二阶泰勒展开。(为什么使用二阶泰勒展开?我这里认为是使精度更高收敛速度更快,参考李宏毅的《机器学习》课程,对损失函数使用泰勒一次展开是梯度下降,而进行