Hello,World!
从去年开始学习Python,在长久的学习过程中,发现了许多有趣的知识,不断充实自己。今天我所写的内容也是极具趣味性,关于优秀的中文分词库——jieba库。
🏔关于Jieba 🐒什么是jieba?1、jieba 是目前表现较为不错的 Python 中文分词组件,它主要有以下特性:
中文文本需要通过分词获得单个的词语jieba需要额外安装jieba库提供三种分词模式2、jieba库的分词原理:利用一个中文词库,确定汉字之间的关联概率,汉字间概率大的组成词组,形成分词结果。除了分词,用户还可以添加自定义的词组。【这一点是很有趣的😄!】
3、jieba库支持四种分词模式:精确模式、全模式、搜索引擎模式、paddle模式,并且支持繁体分词,以及自定义词典。具体介绍:
精确模式,试图将句子最精确地切开,适合文本分析;全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。算法
基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法正文来了!!!
🏔一、安装jieba库🐒1. 此次内容创作,我主要使用的软件有Anaconda,Jupyter Notebook,Pycharm等,看过我之前文章的大佬们,相信对Anaconda都有一个简单的了解,这里就不一一叙述了,直接安装🙂。
因为jieba库不是Anaconda中自带的,所以需要我们自己下载,首先进入jieba库官网:jieba · PyPI![]() https://pypi.org/project/jieba/#files
https://pypi.org/project/jieba/#files
如下图:
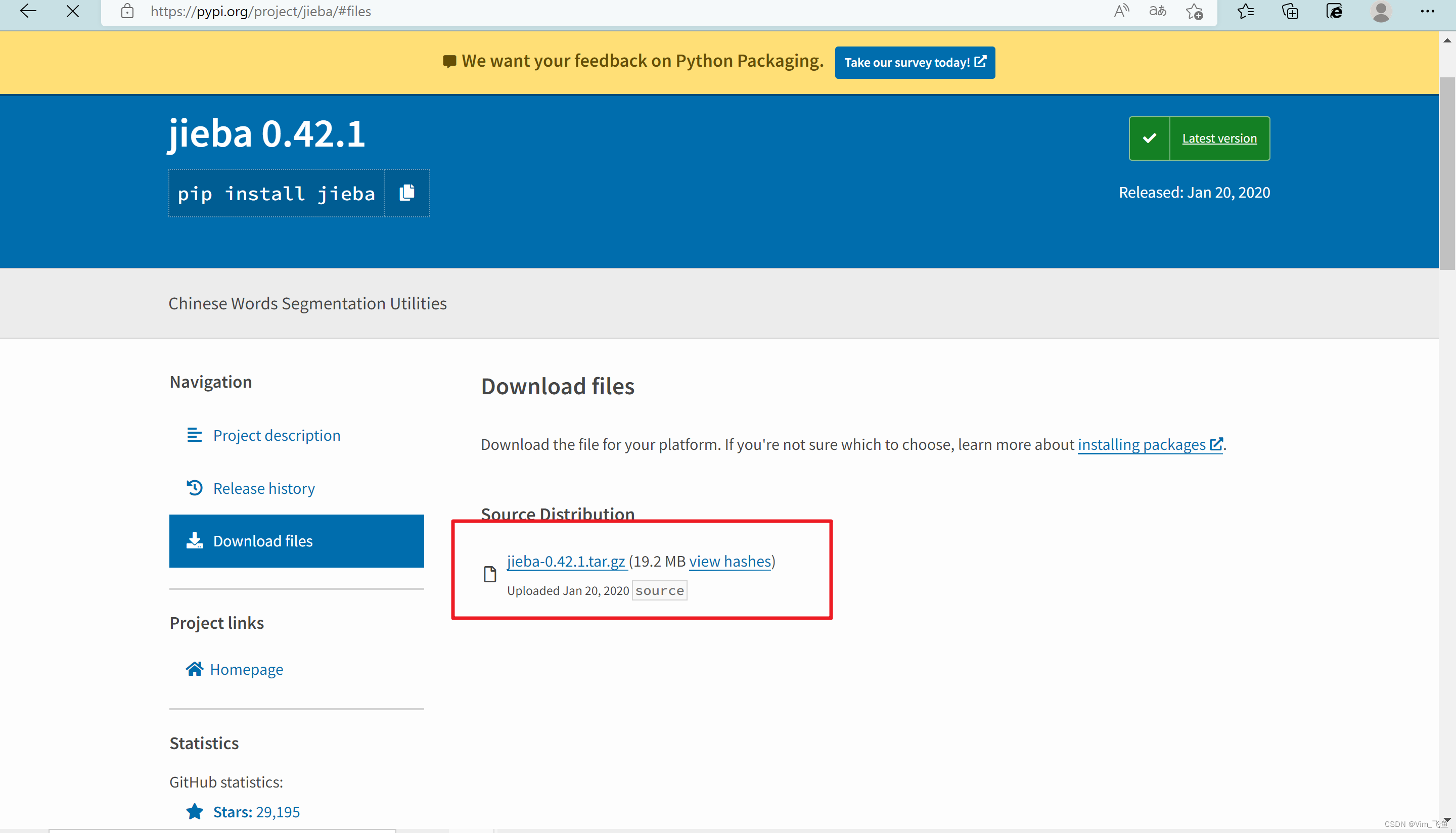
点击官网中文件下载即可(如果下载速度比较慢,可以私聊我!💪)
🐒2. 将压缩包解压到anaconda的pkgs目录。
🐒3. 打开anaconda prompt,切换目录至比如我的D:/anaconda/pkgs/jieba-0.42,输入cmd进入命令行模式 执行 python setup.py install 即可。
🐒4. 再次打开jupyter notebook 测试
import jieba,正常。pycharm中 import jieba ,正常。由此,我们的第一步安装完成!
pip install jiebaimport jieba 🏔二、jieba库的使用 🐒1. 精确模式将语句最精确的切分,不存在冗余数据,适合做文本分析。
#精确模式
jieba.cut(text, cut_all=False)
案例分析:
精确模式分析是不存在冗余数据的,把完整的text文本按照中文词库的标准完成拆分。如图所示:
将语句中所有可能是词的词语都切分出来,速度很快,但是存在冗余数据。
#全模式
jieba.cut(text, cut_all=True)
案例分析:
全模式与精确模式的不同在于,全模式存在冗余数据,是将存在可能的词语全部切分出来,从第一个字到最后一个字遍历作为词语第一个字。例如:以“吉”开头的词语包括“吉林”,“吉林省”,以“长”开头的名词包括“长春”“长春市”等等。如图所示:

不难看出,输出的内容存在冗余数据。
seg_list = jieba.cut("我来到吉林省长春市高新技术产业开发区光谷大街1188号", cut_all=True)print("Full Mode: " + "/ ".join(seg_list)) # 全模式 🐒 3、搜索引擎模式在精确模式的基础上,对长词再次进行切分,提高召回率,适合用于搜索引擎分词。
#搜索引擎模式
jieba.lcut_for_search(text)
案例分析:
搜索引擎模式是将精确模式中的长词,再次按照全模式切分。如图所示:


此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了。
🐒5、自定义词典在jieba自定义字典方面,目前我所了解到的常见的应用环境是各网络平台对违禁词的查询搜索处理,以及网站也对用户个人信息的处理,对购物方面评价信息的处理等等。因此,我同样也使用了jupyter notebook尝试了自定义词典的使用,text文