1.卡方检验是用途非常广的一种假设检验方法,卡方检验中,将任意两行互换,卡方值( )
A.变大
B.变小
C.不变
D.不确定
解析:卡方检验的结果与分类变量的顺序无关,将任意两行进行互换,卡方值不变。
2,在研究数据中,有一个变量“饮料类型”有4 个水平“果汁”、“碳酸饮料”、 “能量饮料”和“其他”,由于该变量的少量数据缺失,那么缺失值用哪种填充 方式会比较好?
A.均值
B.中位数
C.众数
D.调和平均数
解析:这是分类数据,只能用“众数”。
3.在进行缺失值填补时,若数据呈明显的偏态分布,则可考虑采用下列哪种方 法?( )
A.将存在缺失值的样本删除
B.将存在缺失值的变量删除
C.中位数填补
D.均值填补
解析:中位数不受具体数据分布的影响
4.教育水平作为定序型变量,若要描述其离散程度,可选用以下哪种方法( )
A.平均差
B.四分位差
C.方差
D.标准差
解析:另外三种都只能用于描述数值型数据。
5.以下哪个函数用来返回当前的日期及时间
A.NOW
B.TIME
C.DATE
D.TIMENOW
解析:NOW函数用来返回当前的日期及时间信息。
6.以下哪个 SQL 函数可以完成对数字的四舍五入
A.FLOOR
B.CEILING
C.ROUND
D.TRUNCATE
解析:floor(x)表示返回小于 x 的最大整数值(去掉小数取整),ceiling(x)表示返 回大于 x 的最小整数值(进一取整),round(x,y)表示返回参数 x 的四舍五入的 有 y 位小数的值(四舍五入),truncate(x,y)表示返回数字 x 截短为 y 位小数的 结果。
7.以下聚合函数中,使⽤正确的是
A.COUNT(*)
B.MIN(*)
C.MAX(*)
D.SUM(*)
解析:COUNT()函数对给定数据进⾏计数,COUNT(*)表示对表中所有记录进⾏计数;⽽其他聚合函数 只能对给定字段的值进⾏计算。
8.求两个判断条件的交集结果时使用的运算符是
A.加号(+)
B.等号(=)
C.且(AND)
D.或(OR)
9.子查询如果在SQL语句中放错位置是会报错的,子查询可以出现在以下哪个子句中
A.GROUP BY
B.ORDER BY
C.HAVING
D.LIMIT
解析:子查询可以出现在SELECT、WHERE、HAVING、FROM、JOIN子句中。
10.子查询使用的运算符ALL, 表示的意思是
A.满足所有条件
B.满足任意一个条件
C.一个都不满足
D.满足一个条件
解析:IN或NOT IN表示是否在其中,等于其中任意一个条件即可,ALL表示每一个,全部条件都满足。
11.关于子查询的语法规则,正确的是
A.子查询必须放在圆括号里
B.由外到内执行,先执行外部的主查询,再执行内部的子查询
C.可以嵌套无数个子查询
D.所有的子查询都必须添加别名
12.子查询是SQL语句中常用语法,合理的使用子查询可以让代码更简洁。以下关于子查询,说法不正确的是
A.表子查询必须添加表别名
B.引用表子查询中的计算字段,必须添加列别名
C.所有的连接查询都可以替换为子查询
D.所有的子查询都可以替换为连接查询
解析:当WHERE子句的查询条件是聚合函数时,子查询不能替换为连接查询。
13.使用“select * from 表 1 inner join 表 2 on 表 1.员工 id = 表 2.员工id”语句对下边两个表进行查询,查询结果中应有几行数据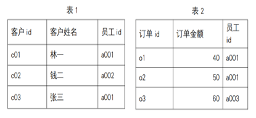
A.2
B.3
C.4
D.5
解析:在连接两表的字段中有重复值且两个字段的值不是一对一匹配关系时
,内连接的结果是把两表中都有的值列出来,并且有重复值的地方进行多对多匹配。
14.使用SQL合并数据简单方便,以下关于SQL中UNION关键字的描述,不正确的是
A.UNION合并数据集的字段个数必须相同
B.UNION合并数据集的字段数据类型必须相同
C.UNION合并数据集的字段顺序必须相同
D.UNION合并后的数据集的行数是合并前的总行数
解析:UNION合并后的数据集的行数是合并前的总行数
15.SQL连接查询时,建⽴连接的关键字段可以有⼏个
A.一个
B.两个
C.多个
D.一个或多个
解析:
连接查询时的连接条件可以是⼀个或多个。
16.别名是SQL中常用的内容,通过别名可以区别不同的表、可以让查询结果可读性增强。在SQL语句中,别名不能出现在哪个⼦句中呢?
A.SELECT
B.WHERE
C.FROM
D.JOIN
解析:在SQL中可以设置表别名和列别名,SQL语句的执⾏顺序是FROM-->-->ON-->JOIN-->WHERE-->GROUP BY-- >HAVING-->SELECT-->ORDER BY,别名是在WHERE⼦句后计算的,所以WHERE⼦句中不能⽤列别名, FROM和JOIN⼦句中可以⽤表别名。
17.SQL语言中每个函数出现的位置都是有要求的,稍有错误就会导致语法错误或者结果数据的计算错误。SQL中的COUNT、SUM、AVG、MAX、MIN等函数,不可以出现在()子句中
A.SELECT
B.WHERE
C.HAVING
D.oRDER BY
解析:由于SQL语句的执行顺序:FROM -> ON -> JOIN -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT -> UNION -> ORDER BY -> LIMIT,WHERE子句中不能用聚合函数。
18.某数据表中包含name字段,现要查找name字段中包含"a"的姓名,下面哪个选项获取的结果最准确().
A.name LIKE ’%a%’
B.name LIKE ’a%’
C.name LIKE ’%a’
D.name LIKE ’_a%’
解析: ’%’可以匹配0个或多个字符,’_’可以匹配一个字符。因此 D选项不如A选项匹配的范围广,比如“huater” 这样的名字 通过'%a%'可以匹配到,但是用'_a%'是匹配不到的。
19。在SQL语句中我们判断数据是否在某个范围内可以使用BETWEEN关键字,现有语句 X BETWEEN 10 AND 20 ,下列与其等价的表达式是()
A.X>10 AND X10 AND X=10 AND X=10 AND X 100 group by id;
解析:
id是发帖人的编号,是唯一的,我们想知道每个会员的发帖数,group by id----按照id分组,就是必然选择。 count(name)是对按照id分组之后的结果计算name的个数。
124.显示发帖数超过5个的语句是
A.select id ,count(name)from t1 group by id;
B.select id ,count(name)from t1 group by id having count(name)>5;
C.select id ,count(name)from t1 group by id having count(name)>5 order by count(name);
D.select id ,count(name)from t1 where id > 100 group by id;
解析:
每个分组计算发帖个数(count(name))之后,我们希望输出结果大于5(count(name)>5)。 这里还是比较好理解的,难度在于对having的理解。我们平时用到条件子句时,它前面的关键词都是where,而这里用的是having。在使用GROUP BY对数据进行分组时需要使用HAVING作为限制条件的关键词。
下面5组数据的观察值(x,y)的组合分别为: (6,6)、(11,9)、(15,12)、(21,17)、(27,16)。
125.尝试绘制散点图观察x与y之间存在何种可能的关系?
A.线性相关关系
B.不相关
C.非线性相关关系
D.无法确定
解析:
观察图像即可发现
126.计算x与y之间的相关系数
A.0.69
B.0.94
C.0.71
D.0.82
解析:
相关系数的计算公式为(x与y的协方差)除以(x和y标准差的乘积),直接计算可得
127.变量x值按一定数量增加时,变量y也按一定数量随之增加,反之亦然,那么x与y之间存在何种关系?
A.负相关关系
B.正相关关系
C.曲线相关关系
D.不确定
解析:
这是典型的正相关关系,反映到计算上就是一个线性函数,反映到图像上就是一条直线
128.在该样本数据中,对相关系数计算结果描述正确的是?
A.说明x与y之间存在低度正相关的线性关系
B.说明x与y之间存在中度正相关的线性关系
C.说明x与y之间存在高度正相关的线性关系
D.说明x与y之间存在高度负相关的线性关系
解析:
相关系数大于0说明正相关,相关系数非常接近于1说明正相关性很强
下图是某公司交易相关的各表连接关系,观察下图回答以下问题:
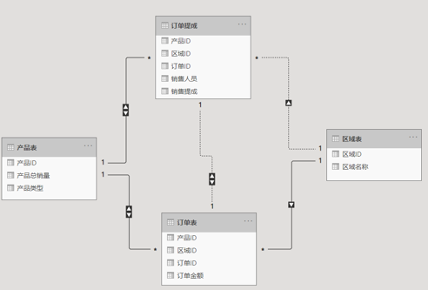

129.订单表与订单提成表都是用来记录交易行为的数据表,从上图中判断订单表与订单提成表间的连接关系是
A.雪花模式
B.星型模式
D.星座模
C.交叉连接
解析:
从订单表到订单提成表有多条筛选路径,所以是交叉连接,所以选C
130.订单表与订单提成表是以交易行为为单位展开记录的数据表,产品表与区域表是围绕产品及区域维度展开记录信息的数据表,在数据库中可以将两表合并为一个表的是
A.产品表与订单表
B.区域表与订单提成表
C.订单提成表与订单表
D.产品表与区域表
解析:
订单表与订单提成表有相同主键订单ID,可以合并为一个表
131.用订单提成表中的销售人员字段筛选订单表中的订单金额字段,按照求和的汇总规则计算出赵大的订单金额合计值应为
A.9000
B.6000
C.3000
D.14000
解析:
订单提成与订单间通过产品表进行跨表筛选,使用类型二的筛选计算规则,赵大有销售过abcd四款产品,所以四款产品的订单金额合计是9000,所以正确选项是A
132.用订单提成表中的销售人员字段筛选订单表中的订单金额字段,按照求和的汇总规则如果想计算出赵大的订单金额合计值为7000的结果,关于有效连接路径的正确描述应是____
A.订单提成与订单表间的连接成为有效连接
B.订单提成与区域表间的连接成为有效连接
C.产品表与订单提成表间的连接成为有效连接
D.订单提成筛选订单时无论有效连接为哪种都无法得到赵大订单金额合计值为7000的结果
解析:
通过订单ID可以直接连接订单提成与订单表,进行筛选按照类型一的方式计算结果,赵大的金额为7000,所以选A
下表是某电商某日各阶段人数统计数据,观察下表回答以下问题:

133.当日UV是多少?
A.1000
B.700
C.500
D.无法计算
解析:
UV是当日到店人数统计,进入首页即为到店,所以选A
134.当日PV是多少?
A.2300
B.1000
C.1300
D.无法计算
解析:
PV是浏览量,以上数据无法统计计算,所以选D
135.当日Vistis是多少?
A.1000
B.700
C.500
D.无法计算
解析:
Vistis是浏览次数,一进一出即为一次流量,以上数据无法统计计算,所以选D
136.该电商最应优先改进的行为可能是?
A.营销方式
B.引流方法
C.促销活动
D.付费流程
解析:
流失人数最多的阶段是加入购物车到完成支付,与该阶段有直接关系的行为是付费流程,所以选D
下图是某企业各表间的E-R关系图,根据下图回答以下问题:

137.根据各表中字段内容及连接关系判断上图可能描述的企业是
A.银行
B.电商
C.游戏
D.物流
解析:
根据各表中字段内容及连接关系判断上图可能描述的企业是
138.根据上图连接关系判断,上图Orderinfo可以筛选的表是
A.Userinfo
B.Goodsinfo
C.Orderdetail
D.Regioninfo
解析:
Orderinfo与Orderdetail是一对多的关系,所以选C
139.根据上图各表字段内容及连接关系判断,上图反映的业务模块是
A.进销存
B.人货场
C.流量、转化、客单价
D.以上都不是
解析:
上图描述的是服装电商中人货场的业务场景,所以选B
140.Goodsbrand表中记录了产品的品牌信息,根据上图各表内容及连接关系判断,上图中Goodsbrand不能筛选的表是
A.Goodsinfo
B.Orderdetail
C.Orderinfo
D.以上全是
解析:
Orderinfo用来连接客户一侧内容,没有展开到产品层级,所以不能与Goodsbrand产生筛选逻辑,所以选C