一、选题的背景
选择此选题是因为掌上高考是一个提供本科院校信息的网站,通过爬取该网站的数据,可以获取到各个本科院校的相关信息,如学校名称、所在地、专业设置等。通过对这些数据进行分析和可视化,可以帮助学生更好地了解各个本科院校的情况,为他们的升学选择提供参考。预期目标是通过数据分析,找出各个本科院校的特点和优势,以及不同地区、不同专业的分布情况,为学生提供更全面、准确的信息。从社会方面来看,这有助于提高学生的就业竞争力;从经济方面来看,这有助于促进教育产业的发展;从技术方面来看,这需要运用爬虫技术和数据分析技术;数据来源主要是掌上高考网站。
二、主题式网络爬虫设计方案
1. 主题式网络爬虫名称:掌上高考高校数据爬取与可视化爬虫
2. 主题式网络爬虫爬取的内容与数据特征分析:
- 爬取内容:掌上高考网站上的高校数据,包括高校名称、所在地、类型(综合类、理工类等)、排名、学科门类等信息。
- 数据特征分析:高校数据具有结构化特点,可以通过HTML标签和属性进行定位和提取。同时,由于高校数据的多样性,需要对不同类型的高校进行分类处理
3. 主题式网络爬虫设计方案概述:
- 实现思路:
(1). 确定目标网站:掌上高考网站。
(2). 分析网页结构:使用浏览器开发者工具查看网页源代码,分析大学数据的HTML标签和属性。
(3). 编写爬虫代码:根据分析结果,使用Python的第三方库编写爬虫代码,实现对高校数据的爬取。
(4). 数据清洗与存储:对爬取到的数据进行清洗和格式化处理,将数据存储到合适的数据结构中,如列表、字典等。
(5). 数据可视化:使用Python的可视化库对高校数据进行可视化展示,如绘制柱状图、折线图等。
- 技术难点:
(1). 动态加载:部分网页数据是通过JavaScript动态加载的,需要使用Selenium等工具模拟浏览器操作,获取动态加载的数据。
(2). 反爬机制:目标网站可能采用反爬机制,如设置User-Agent、限制访问频率等,需要使用代理IP、设置请求头等方式绕过反爬策略。
(3). 数据清洗:爬取到的数据可能存在缺失值、异常值等问题,需要进行数据清洗和预处理,确保数据的准确性和完整性。
三、主题页面的结构特征分析
1.主题页面的结构与特征分析:

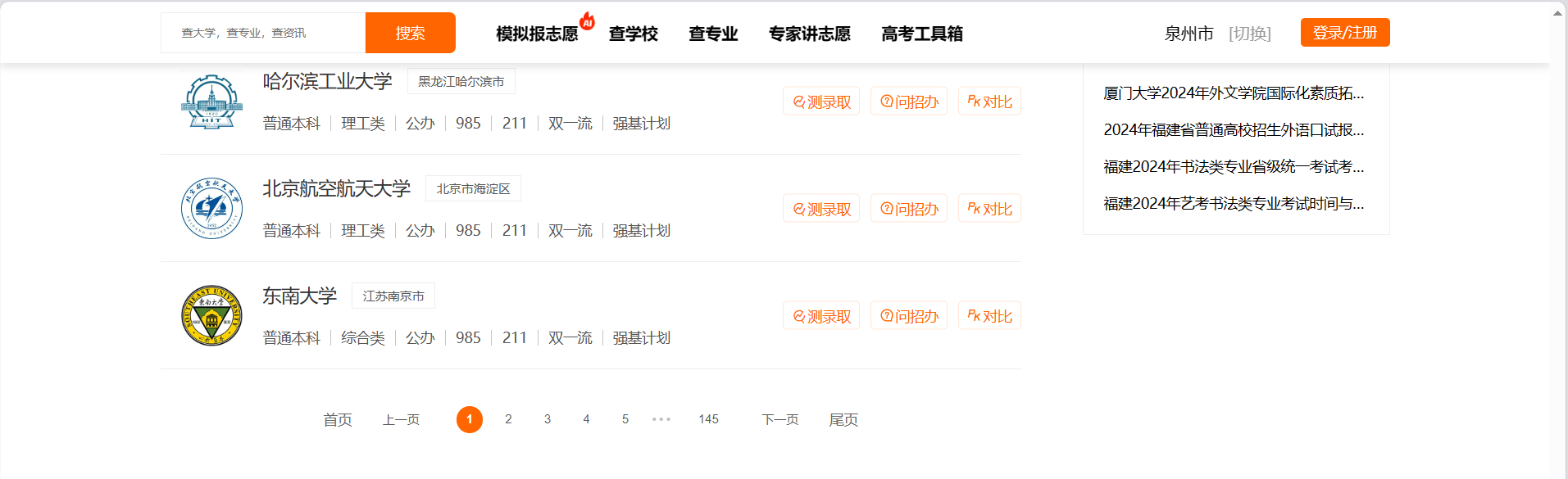
(1).主题页面包含多个大学的信息、
(2).每个大学的信息包括学校名称、所在地、类型、排名等。
(3).页面中可能存在分页功能,需要翻页获取