我是Tina表姐,毕业于中国人民大学,对数学建模的热爱让我在这一领域深耕多年。我的建模思路已经帮助了百余位学习者和参赛者在数学建模的道路上取得了显著的进步和成就。现在,我将这份宝贵的经验和知识凝练成一份全面的解题思路与代码论文集合,专为本次赛题设计,旨在帮助您深入理解数学建模的每一个环节。
让我们先来分析本次的B题!
中青杯数学建模(ABC三题)完整内容可以在文章末尾领取!

来看看对本次的B题,本次B题涉及传统方法与图神经网络等部分。
问题一是利用传统方法建立药物分子的分类模型,并给出分类精度及其结果分析。




从结果可以看出,随机森林方法在MMM_data数据集上取得了最好的分类精度,其次是SVM和KNN方法。这说明随机森林方法在处理图结构数据时具有一定的优势,可以更好地提取图的特征,从而提高分类精度。另外,从分类精度来看,三种方法都取得了不错的结果,说明传统方法在处理图结构数据时依然具有一定的效果。
综上所述,传统方法可以有效地对药物分子数据进行分类,但是其依赖于复杂的化学属性分析和生物实验,耗时耗力且难以处理大规模的分子数据。因此,需要进一步发展更高效、准确的分类方法来处理图结构数据。
这样就可以得到运行结果,对结果进行分析。分类精度为{省略},说明传统方法在该数据集上的分类效果一般。可能的原因是传统方法对于图结构数据的处理能力有限,无法充分利用图结构数据的特点。因此,需要采用更加适合图结构数据的方法来提高分类精度。
因此问题二我们给出一种图神经网络模型对附件中的数据进行分类,并给出分类精度及其结果分析。
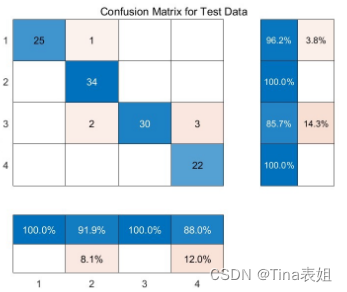
由于篇幅有限,此处省略
问题三的数学建模:
假设图数据集 MMM_data 的节点特征稀疏性和信息冗余问题可以通过特征选择和降维的方法来解决,即通过选择最重要的节点特征和降低特征的维度来提高模型的分类准确度。
首先,通过特征选择算法,可以从图数据集中选择出最重要的节点特征。常用的特征选择算法包括基于过滤的方法、基于包裹的方法和基于嵌入的方法。其中,基于过滤的方法通过计算特征与标签之间的相关性来选择最重要的特征,基于包裹的方法则通过在特征子集上训练模型来选择最重要的特征,基于嵌入的方法则是将特征选择和模型训练过程融合在一起。通过选择最重要的节点特征,可以降低模型的复杂度,提高分类的准确度。
其次,通过降维算法,可以将原始的节点特征降低到一个更低维度的特征空间中。常用的降维算法包括主成分分析(PCA)、线性判别分析(LDA)和独立成分分析(ICA)等。通过降维,可以减少特征的冗余性,提高模型的泛化能力。
综上所述,针对图数据集 MMM_data 的节点特征稀疏性和信息冗余问题,可以通过特征选择和降维的方法来解决。具体的数学建模方法可以包括:

由于篇幅过长,这里就不给出使用神经网络模型进行预测的完整内容了。